“Learn TCP/IP in a Weekend” introduces the fundamental TCP/IP model and compares it to the OSI model, emphasizing data encapsulation and fragmentation. It explains the four layers of TCP/IP, their functions, associated protocols like TCP and IP, and concepts such as protocol binding and MTU black holes. The course further covers essential TCP/IP protocols like UDP, ARP, RARP, ICMP, and IGMP, detailing their roles in network communication. Additionally, it explains IP addressing, subnetting, and the distinction between IPv4 and IPv6, including addressing schemes, classes, reserved addresses, and subnet masks. Finally, the material examines common TCP/IP tools and commands for network diagnostics and configuration, along with principles of remote access and security using IPSec.
Network Fundamentals Study Guide
Quiz
- Explain the process of IP fragmentation. When does it occur, and how does the receiving end handle it? IP fragmentation occurs when a transmitting device sends a datagram larger than the MTU of a network device along the path. The transmitting internet layer divides the datagram into smaller fragments. The receiving end’s internet layer then reassembles these fragments based on information in the header, such as the “more fragments” bit.
- Describe what a black hole router is and why it poses a problem for network communication. A black hole router is a router that receives a datagram larger than its MTU and should send an ICMP “destination unreachable” message back, but this message is blocked (often by a firewall). As a result, the sender never receives notification of the problem, and the data is lost without explanation, disappearing as if into a black hole.
- What is the purpose of the MAC address, and how is it structured? The MAC (Media Access Control) address is a 48-bit hexadecimal universally unique identifier that serves as the physical address of a network interface card (NIC). It’s structured into two main parts: the first part is the OUI (Organizational Unique Identifier), which identifies the manufacturer, and the second part is specific to that individual device.
- Outline the key components of an Ethernet frame and their functions. An Ethernet frame includes the preamble (synchronization), the start of frame delimiter (indicates the beginning of data), the destination MAC address (recipient’s physical address), and the source MAC address (sender’s physical address). These components ensure proper delivery and identification of the data on a local network.
- Explain the primary functions of ARP (Address Resolution Protocol) and RARP (Reverse Address Resolution Protocol). ARP is used to resolve an IP address to its corresponding MAC address on a local network, enabling communication between devices. RARP performs the opposite function, mapping a MAC address to its assigned IP address, though it is less commonly used today.
- What is the role of ICMP (Internet Control Message Protocol) in networking? Provide an example of its use. ICMP is a protocol used to send messages related to the status of a system and for diagnostic or testing purposes, rather than for sending regular data. An example of its use is the ping utility, which uses ICMP echo requests and replies to determine the connectivity status of a target system.
- Differentiate between TCP (Transmission Control Protocol) and UDP (User Datagram Protocol). TCP is a connection-oriented protocol that provides reliable, ordered, and error-checked delivery of data through mechanisms like acknowledgements and retransmissions. UDP is a connectionless protocol that offers faster, less overhead communication but does not guarantee delivery or order.
- Describe the three main port ranges defined by the IANA (Internet Assigned Numbers Authority). The three main port ranges are: well-known ports (1-1023), which are assigned to common services; registered ports (1024-49151), which can be registered by applications; and dynamic or private ports (49152-65535), which are used for temporary connections and unregistered services.
- Explain the purpose of a subnet mask and how it helps in network segmentation. A subnet mask is a 32-bit binary number that separates the network portion of an IP address from the host portion. By defining which bits belong to the network and which belong to the host, it enables the creation of subnets, which are smaller logical divisions within a larger network, improving organization and efficiency.
- What is a default gateway, and why is it necessary for a device to communicate with hosts on different networks? A default gateway is the IP address of a router on the local network that a device sends traffic to when the destination IP address is outside of its own network. It acts as a forwarding point, allowing devices on one network to communicate with devices on other networks by routing traffic appropriately.
Essay Format Questions
- Discuss the evolution from IPv4 to IPv6, highlighting the key limitations of IPv4 that necessitated the development of IPv6 and the primary advantages offered by the newer protocol.
- Compare and contrast the TCP/IP model with the OSI model, explaining the layers in each model and how they correspond to one another in terms of network functionality.
- Analyze the importance of network security protocols such as IPSec in maintaining data confidentiality, integrity, and availability in modern network environments.
- Describe the role of dynamic IP addressing using DHCP in network administration, including the benefits and potential challenges compared to static IP addressing.
- Evaluate the significance of various TCP/IP tools and commands (e.g., ping, traceroute, nslookup) in network troubleshooting, diagnostics, and security analysis.
Glossary of Key Terms
- Datagram: A basic unit of data transfer in a packet-switched network, particularly in connectionless protocols like IP and UDP.
- MTU (Maximum Transmission Unit): The largest size (in bytes) of a protocol data unit that can be transmitted in a single network layer transaction.
- Fragmentation: The process of dividing a large datagram into smaller pieces (fragments) to accommodate the MTU limitations of network devices along the transmission path.
- Reassembly: The process at the receiving end of reconstructing the original datagram from its fragmented pieces.
- Flag Bits (DF and MF): Fields within the IP header used during fragmentation. The DF (Don’t Fragment) bit indicates whether fragmentation is allowed, and the MF (More Fragments) bit indicates if there are more fragments to follow.
- Black Hole Router: A router that drops datagrams that are too large without sending an ICMP “destination unreachable” message back to the source, typically due to a blocked ICMP response.
- ICMP (Internet Control Message Protocol): A network layer protocol used for error reporting and diagnostic functions, such as the ping utility.
- Network Interface Layer (TCP/IP): The lowest layer in the TCP/IP model, responsible for the physical transmission of data across the network medium; corresponds to the Physical and Data Link layers of the OSI model.
- Frame: A data unit at the Data Link layer of the OSI model (and conceptually at the Network Interface Layer of TCP/IP), containing header and trailer information along with the payload (data).
- MAC Address (Media Access Control Address): A unique 48-bit hexadecimal identifier assigned to a network interface card for communication on a local network.
- OUI (Organizational Unique Identifier): The first 24 bits of a MAC address, identifying the manufacturer of the network interface.
- Preamble: A 7-byte (56-bit) sequence at the beginning of an Ethernet frame used for synchronization between the sending and receiving devices.
- Start of Frame Delimiter (SFD): A 1-byte (8-bit) field in an Ethernet frame that signals the beginning of the actual data transmission.
- TCP (Transmission Control Protocol): A connection-oriented, reliable transport layer protocol that provides ordered and error-checked delivery of data.
- IP (Internet Protocol): A network layer protocol responsible for addressing and routing packets across a network.
- UDP (User Datagram Protocol): A connectionless, unreliable transport layer protocol that offers faster communication with less overhead than TCP.
- ARP (Address Resolution Protocol): A protocol used to map IP addresses to their corresponding MAC addresses on a local network.
- RARP (Reverse Address Resolution Protocol): A protocol used (less commonly today) to map MAC addresses to IP addresses.
- IGMP (Internet Group Management Protocol): A protocol used by hosts and routers to manage membership in multicast groups.
- Multicast: A method of sending data to a group of interested recipients simultaneously.
- Unicast: A method of sending data from one sender to a single receiver.
- Binary: A base-2 number system using only the digits 0 and 1.
- Decimal: A base-10 number system using the digits 0 through 9.
- Octet: An 8-bit unit of data, commonly used in IP addressing.
- Port (Networking): A logical endpoint for communication in computer networking, identifying a specific process or application.
- IANA (Internet Assigned Numbers Authority): The organization responsible for the global coordination of IP addresses, domain names, and protocol parameters, including port numbers.
- Well-Known Ports: Port numbers ranging from 0 to 1023, reserved for common network services and protocols.
- Registered Ports: Port numbers ranging from 1024 to 49151, which can be registered by applications.
- Dynamic/Private Ports: Port numbers ranging from 49152 to 65535, used for temporary or private connections.
- FTP (File Transfer Protocol): A standard network protocol used for the transfer of computer files between a client and server on a computer network.
- NTP (Network Time Protocol): A protocol used to synchronize the clocks of computer systems over a network.
- SMTP (Simple Mail Transfer Protocol): A protocol used for sending email between mail servers.
- POP3 (Post Office Protocol version 3): An application layer protocol used by email clients to retrieve email from a mail server.
- IMAP (Internet Message Access Protocol): An application layer protocol used by email clients to access email on a mail server.
- NNTP (Network News Transfer Protocol): An application layer protocol used for transporting Usenet news articles.
- HTTP (Hypertext Transfer Protocol): The foundation of data communication for the World Wide Web.
- HTTPS (Hypertext Transfer Protocol Secure): A secure version of HTTP that uses encryption (SSL/TLS) for secure communication.
- RDP (Remote Desktop Protocol): A proprietary protocol developed by Microsoft which provides a user with a graphical interface to connect to another computer over a network connection.
- DNS (Domain Name System): A hierarchical and decentralized naming system for computers, services, or other resources connected to the Internet or a private network, translating domain names to IP addresses.
- FQDN (Fully Qualified Domain Name): A complete domain name that uniquely identifies a host on the Internet.
- WINS (Windows Internet Naming Service): A Microsoft service for NetBIOS name resolution on a network.
- NetBIOS (Network Basic Input/Output System): A networking protocol that provides services related to the transport and session layers of the OSI model.
- IPv4 (Internet Protocol version 4): The fourth version of the Internet Protocol, using 32-bit addresses.
- Octet (in IP addressing): One of the four 8-bit sections of an IPv4 address, typically written in decimal form separated by dots.
- Subnetting: The practice of dividing a network into smaller subnetworks (subnets) to improve network organization and efficiency.
- Subnet Mask: A 32-bit number that distinguishes the network portion of an IP address from the host portion, used in IP configuration to define the subnet.
- Network ID: The portion of an IP address that identifies the network to which the host belongs.
- Host ID: The portion of an IP address that identifies a specific device (host) within a network.
- ANDing (Bitwise AND): A logical operation used in subnetting to determine the network address by comparing the IP address and the subnet mask in binary form.
- Classful IP Addressing: An older system of IP addressing that divided IP addresses into five classes (A, B, C, D, E) with predefined network and host portions.
- Classless IP Addressing (CIDR – Classless Inter-Domain Routing): A more flexible IP addressing system that allows for variable-length subnet masks (VLSM), indicated by a slash followed by the number of network bits (e.g., /24).
- Reserved IP Addresses: IP addresses that are not intended for public use and have special purposes (e.g., loopback address 127.0.0.1).
- Private IP Addresses: Ranges of IP addresses defined for use within private networks, not routable on the public internet (e.g., 192.168.x.x).
- Public IP Addresses: IP addresses that are routable on the public internet and are typically assigned by an ISP.
- Loopback Address: An IP address (127.0.0.1 for IPv4, ::1 for IPv6) used for testing the network stack on a local machine.
- Broadcast Address: An IP address within a network segment that is used to send messages to all devices in that segment (e.g., the last address in a subnet).
- Default Gateway: The IP address of a router that serves as an access point to other networks, typically the internet.
- VLSM (Variable Length Subnet Mask): A subnetting technique that allows different subnets within the same network to have different subnet masks, enabling more efficient use of IP addresses.
- CIDR (Classless Inter-Domain Routing): An IP addressing scheme that replaces the older classful addressing architecture, using VLSM and representing networks by an IP address and a prefix length (e.g., 192.168.1.0/24).
- Supernetting: The process of combining multiple smaller network segments into a larger network segment, often using CIDR notation with a shorter prefix length.
- IPv6 (Internet Protocol version 6): The latest version of the Internet Protocol, using 128-bit addresses, intended to address the limitations of IPv4.
- Hexadecimal: A base-16 number system using the digits 0-9 and the letters A-F.
- IPv6 Address Format: Consists of eight groups of four hexadecimal digits, separated by colons.
- IPv6 Address Compression: Rules for shortening IPv6 addresses by omitting leading zeros and replacing consecutive zero groups with a double colon (::).
- Global Unicast Address (IPv6): A publicly routable IPv6 address, similar to public IPv4 addresses.
- Unique Local Address (IPv6): An IPv6 address intended for private networks, not globally routable.
- Link-Local Address (IPv6): An IPv6 address that is only valid within a single network link, often starting with FE80.
- Multicast Address (IPv6): An IPv6 address that identifies a group of interfaces, used for one-to-many communication.
- Anycast Address (IPv6): An IPv6 address that identifies a set of interfaces (typically belonging to different nodes), with packets addressed to an anycast address being routed to the nearest interface in the set.
- EUI-64 (Extended Unique Identifier-64): A method for automatically configuring IPv6 interface IDs based on the 48-bit MAC address, with a 64-bit format.
- Neighbor Discovery Protocol (NDP): A protocol used by IPv6 nodes to discover other nodes on the same link, determine their link-layer addresses, find available routers, and perform address autoconfiguration.
- Router Solicitation (RS): An NDP message sent by a host to request routers to send router advertisements immediately.
- Router Advertisement (RA): An NDP message sent by routers to advertise their presence, link parameters, and IPv6 prefixes.
- Neighbor Solicitation (NS): An NDP message sent by a node to determine the link-layer address of a neighbor or to verify that a neighbor is still reachable.
- Neighbor Advertisement (NA): An NDP message sent by a node in response to a neighbor solicitation or to announce a change in its link-layer address.
- DAD (Duplicate Address Detection): A process in IPv6 used to ensure that a newly configured unicast address is unique on the link.
- DHCPv6 (Dynamic Host Configuration Protocol for IPv6): A network protocol used by IPv6 hosts to obtain configuration information such as IPv6 addresses, DNS server addresses, and other configuration parameters from a DHCPv6 server.
- Tunneling (Networking): A technique that allows network packets to be encapsulated within packets of another protocol, often used to transmit IPv6 traffic over an IPv4 network.
- ISATAP (Intra-Site Automatic Tunnel Addressing Protocol): An IPv6 transition mechanism that allows IPv6 hosts to communicate over an IPv4 network by encapsulating IPv6 packets within IPv4 packets.
- 6to4: An IPv6 transition mechanism that allows IPv6 networks to communicate over the IPv4 Internet without explicit configuration of tunnels.
- Teredo: An IPv6 transition mechanism that provides IPv6 connectivity to IPv6-aware hosts that are located behind NAT devices and have only IPv4 connectivity to the Internet.
- Netstat: A command-line utility that displays network connections, listening ports, Ethernet statistics, the IP routing table, IPv4 statistics (for IP, ICMP, TCP, and UDP protocols), IPv6 statistics (for IPv6, ICMPv6, TCP over IPv6, and UDP over IPv6), and network interface statistics.
- Nbtstat: A command-line utility used to diagnose NetBIOS name resolution problems.
- Nslookup: A command-line tool used to query the Domain Name System (DNS) to obtain domain name or IP address mapping information.
- Dig (Domain Information Groper): A network command-line tool used to query DNS name servers.
- Ping: A network utility used to test the reachability of a host on an Internet Protocol (IP) network by sending ICMP echo request packets to the target host and listening for ICMP echo reply packets in return.
- Traceroute (or Tracert on Windows): A network diagnostic tool for displaying the route (path) and measuring transit delays of packets across an Internet Protocol (IP) network.
- Protocol Analyzer (Network Analyzer/Packet Sniffer): A tool used to capture and analyze network traffic, allowing inspection of the contents of individual packets.
- Port Scanner: A program used to probe a server or host for open ports, often used for security assessments or by attackers to find potential entry points.
- ARP Command: A command-line utility used to view and modify the Address Resolution Protocol (ARP) cache of a computer.
- Route Command: A command-line utility used to display and manipulate the IP routing table of a computer.
- DHCP (Dynamic Host Configuration Protocol): A network protocol that enables a server to automatically assign IP addresses and other network configuration parameters to devices on a network.
- DHCP Scope: The range of IP addresses that a DHCP server is configured to lease to clients on a network.
- DHCP Lease: The duration of time for which a DHCP client is allowed to use an IP address assigned by a DHCP server.
- Static IP Addressing: Manually configuring an IP address and other network settings on a device, which remains constant unless manually changed.
- Dynamic IP Addressing: Obtaining an IP address and other network settings automatically from a DHCP server.
- APIPA (Automatic Private IP Addressing): A feature in Windows that automatically assigns an IP address in the 169.254.x.x range to a client when a DHCP server is unavailable.
- VPN (Virtual Private Network): A network that uses a public telecommunications infrastructure, such as the internet, to provide remote offices or individual users with secure access to their organization’s network.
- Tunneling (in VPNs): The process of encapsulating data packets within other packets to create a secure connection (tunnel) across a public network.
- RADIUS (Remote Authentication Dial-In User Service): A networking protocol that provides centralized Authentication, Authorization, and Accounting (AAA) management for users who connect to and use a network service.
- TACACS+ (Terminal Access Controller Access-Control System Plus): A Cisco-proprietary protocol that provides centralized authentication, authorization, and accounting (AAA) for network access.
- Diameter: An authentication, authorization, and accounting protocol that is intended to overcome some of the limitations of RADIUS.
- AAA (Authentication, Authorization, Accounting): A security framework that controls who is permitted to use a network (authentication), what they can do once they are on the network (authorization), and keeps a record of their activity (accounting).
- IPSec (IP Security): A suite of protocols used to secure Internet Protocol (IP) communications by authenticating and/or encrypting each IP packet of a communication session.
- AH (Authentication Header): An IPSec protocol that provides data origin authentication, data integrity, and anti-replay protection.
- ESP (Encapsulating Security Payload): An IPSec protocol that provides confidentiality (encryption), data origin authentication, data integrity, and anti-replay protection.
- Security Association (SA): A simplex (one-way) connection established between a sender and a receiver that provides security services. IPSec peers establish SAs for secure communication.
- IKE (Internet Key Exchange): A protocol used to establish security associations (SAs) in IPSec.
- IPSec Policy: A set of rules that define how IPSec should be applied to network traffic, including which traffic should be protected and what security services should be used.
Briefing Document: Network Fundamentals and Security
Date: October 26, 2023 Prepared For: [Intended Audience – e.g., Network Engineering Team, Security Analysts] Prepared By: Gemini AI Subject: Review of Network Fundamentals, Addressing, Protocols, Tools, and Security Concepts from Provided Sources
This briefing document summarizes the key themes, important ideas, and facts discussed in the provided excerpts, covering fundamental networking concepts, IP addressing (both IPv4 and IPv6), essential networking protocols and tools, remote access methods, and security principles.
Main Themes and Important Ideas
1. Data Transmission and Fragmentation (01.pdf)
- When network devices encounter datagrams larger than their Maximum Transmission Unit (MTU), the transmitting internet layer fragments the data into smaller blocks for easier transit.
- “In these instances when there is a datagramgram that’s larger than the MTU of a device the transmitting internet layer fragments the data or the datagramgram and then tries to resend it in smaller and more easily manageable blocks.”
- The header of fragmented datagrams contains flag bits: a reserved bit (always zero), the “Don’t Fragment” (DF) bit (on or off), and the “More Fragments” (MF) bit (on if more fragments are coming, off otherwise).
- “The second is the don’t fragment or the DF bit Now either this bit is off or zero which means fragment this datagram or on meaning don’t fragment this datagram The third flag bit is the more fragments bit MF And when this is on it means that there are more fragments on the way And finally when the MF flag is off it means there are no more fragments to be sent as you can see right here And that there were never any fragments to send.”
- A “black hole router” occurs when a datagram with an MTU larger than a receiving device’s MTU is sent, and the expected ICMP response notifying the sender of the mismatch is blocked (e.g., by a firewall), leading to data loss.
- “Now a black hole router is the name given to a situation where a datagramgram is sent with an MTU that’s greater than the MTU of the receiving device as we can see here. Now when the destination device is unable to receive the IP datagramgram it’s supposed to send a specific ICMP response that notifies the transmitting station that there’s an MTU mismatch. This can be due to a variety of reasons one of which could be as simple as a firewall that’s blocking the MP response. … In these cases this is called a black hole because of the disappearance of datagramgrams…”
- The ping utility can be used to detect MTU black holes by specifying the MTU size in the ICMP echo request.
- “And one of the best ways is to use the ping utility and specify a syntax that sets the MTU of the ICMP echo request meaning you tell it I want to ping with this much of an MTU And so then we can see if the ping’s not coming back if it’s coming back at one MTU and not another then we know oh this is what’s happening right here.”
2. Network Interface Layer and Ethernet Frames (01.pdf)
- The network interface layer (bottom of TCP/IP stack) handles the physical transfer of bits across the network medium and corresponds to the physical and data link layers of the OSI model.
- Data at this layer is referred to as “frames,” and major functions include layer 2 switching operations based on MAC addresses.
- A MAC (Media Access Control) address is a 48-bit hexadecimal universally unique identifier, composed of the Organizational Unique Identifier (OUI) and a device-specific part.
- “A MAC address again is a 48 bit hexadesimal universally unique identifier that’s broken up into several parts The first part of it is what we call the OUI or the organizational unique identifier This basically says what company is uh sending out this device And then we have the second part which is the nick specific…”
- The structure of an Ethernet frame includes:
- Preamble (7 bytes/56 bits): Synchronization.
- Start of Frame Delimiter: Indicates the start of data.
- Source and Destination MAC Addresses (12 bytes/96 bits total).
- “The preamble of an Ethernet frame is made up of seven bytes or 56 bits And this serves as synchronization and gives the receiving station a heads up to standby and look out for a signal that’s coming The next part is what we call the start of frame delimiter The only purpose of this is to indicate the start of data The next two parts are the source and destination MAC addresses…”
3. TCP/IP Protocol Suite and Core Protocols (01.pdf)
- The TCP/IP protocol suite includes essential protocols like TCP (connection-oriented, reliable), IP (connectionless, routing), UDP (connectionless, fast), ARP (IP to MAC address mapping), RARP (MAC to IP address mapping), ICMP (status and error messages), and IGMP (multicast group management).
- ARP resolves IP addresses to MAC addresses for local network communication. If the MAC address isn’t in the ARP cache, a broadcast is sent. The target device responds with a unicast containing its MAC address, which is then added to the ARP table.
- “The ARP process works by first uh receiving the IP address from IP or the internet protocol Then ARP has the MAC address in its cached table So the router has what are called ARP tables that link IP addresses to MAC addresses We call this the ARP table It looks in there to see if it know if it has a MAC address for the IP address listed It then sends it back to the IP if it uh if it does have it And if it doesn’t have it it broadcasts the message it’s sent in order to resolve what we call resolve the address to a MAC address And the target computer with the IP address responds to that broadcast message with what’s called a uniccast message… that contains the MAC address that it’s seeking ARP then will add the MAC address to its table.”
- ICMP (Internet Control Message Protocol) is used for diagnostic and testing purposes (e.g., ping, traceroute) and to report errors (e.g., MTU black hole notification). It operates at the internet layer.
- “ICMP which is also called the internet control message protocol It’s a protocol designed to send messages that relate to the status of a system It’s not meant to actually send data So ICMP messages are used generally speaking for diagnostic and testing purposes Now they can also be used as a response to errors that occur in the normal operations of IP And if you recall one of the times that we talked about that was for instance with the MTU black hole when that MP message couldn’t get back to the original router.”
- IGMP (Internet Group Management Protocol) manages membership in multicast groups, allowing one-to-many communication.
4. IP Packet Delivery and Binary/Decimal Conversion (01.pdf)
- IP packet delivery involves resolving the host name to an IP address (using services like DNS), establishing a connection at the transport layer, determining if the destination is local or remote based on the subnet mask, and then routing and delivering the packet.
- Understanding binary (base 2) and decimal (base 10) conversions is crucial for IP addressing and subnetting. Binary uses 0s and 1s, while decimal uses 0-9. An octet is an 8-bit binary number.
- Conversion between binary and decimal involves understanding the place values (powers of 2 for binary, powers of 10 for decimal).
5. Network Ports and Protocols (01.pdf)
- A network port is a process-specific or application-specific designation that serves as a communication endpoint in a computer’s operating system.
- The Internet Assigned Numbers Authority (IANA) regulates port assignments, which range from 0 to over 65,000 (port 0 is reserved).
- Port ranges are divided into three subsets:
- Well-known ports (1-1023): Used by common services.
- Registered ports (1024-49151): Reserved by applications that register with IANA.
- Dynamic/private ports (49152-65535): Used by unregistered services and for temporary connections.
- Key well-known ports and their associated protocols include:
- 7: Echo (used by ping).
- 20, 21: FTP (File Transfer Protocol) – data and control.
- 22: SSH (Secure Shell).
- 23: Telnet.
- 25: SMTP (Simple Mail Transfer Protocol) – sending email.
- 53: DNS (Domain Name Service).
- 67, 68: DHCP (Dynamic Host Configuration Protocol) and BOOTP.
- 69: TFTP (Trivial File Transfer Protocol).
- 80: HTTP (Hypertext Transfer Protocol).
- 110: POP3 (Post Office Protocol version 3) – receiving email.
- 143: IMAP (Internet Message Access Protocol) – accessing email.
- 443: HTTPS (HTTP Secure).
- 3389: RDP (Remote Desktop Protocol).
- 123: NTP (Network Time Protocol).
- 119: NNTP (Network News Transfer Protocol).
6. Network Addressing: Names, Addresses, and IPv4 (01.pdf)
- Devices communicate using network addresses (IP addresses). Naming services map network names (e.g., hostnames, domain names) to these addresses.
- Common network naming services:
- DNS (Domain Name Service): Used on the internet and most networks to translate fully qualified domain names (FQDNs) to IP addresses.
- WINS (Windows Internet Naming Service): Outdated Windows-specific service.
- NetBIOS: Broadcast-based service used on Windows networks.
- IPv4 addresses are 32-bit binary addresses, typically represented in dotted decimal format (four octets).
- “IPv4 IP version 4 addresses is a very important aspect of networking for any administrator or uh technician or even just uh you know IT guy to understand It is a 32bit binary address that’s used to identify and differentiate nodes on a network In other words it is your address on the network or your social security number with the IPv4 addressing scheme being a 32bit address And you can see if we counted each one of these up remember a bit is either zero or one And we can count up there are 32 of these.”
- Theoretically, IPv4 allows for approximately 4.29 billion unique addresses.
- IP addresses are managed by IANA (Internet Assigned Numbers Authority) and Regional Internet Registries (RIRs).
7. Subnetting and Subnet Masks (01.pdf)
- Subnetting divides a larger network into smaller subnetworks to improve routing efficiency, management, and security.
- A subnet mask is a 32-bit binary address (similar to an IP address) used to separate the network portion from the node portion of an IP address.
- “A subnet mask is like an IP address a 32bit binary address broken up into four octets in a dotted decimal format just like an IP address And it’s used to separate the network portion from the node portion I’m going to show you how that works in just a minute.”
- Applying a subnet mask to an IP address using a bitwise AND operation reveals the network ID.
- “When a subnet mask is applied to an IP address the remainder is the network portion Meaning when we take the IP address and we apply the subnet mask and I’ll show you how to do that in a second what we get as a remainder what’s left over is going to be the network ID This allows us to then determine what the node ID is This will make more sense in just a minute The way we do this is through something called ending Anding is a mathematics term It really has to do with logic The way it works is and you just have to sort of remember these rules One and one is one One and zero is zero And the trick there is that that zero is there 0 and 1 is zero And 0 and 0 is also zero So basically what ending does is allows us to hide certain um address certain bits from the rest of the network and therefore we’re allowed to get uh the IP address uh or rather the network address from the node address.”
- Rules for subnet masks: Ones are always contiguous from the left, and zeros are always contiguous from the right.
- Default subnet masks correspond to IP address classes.
- Custom subnet masks allow for further division of networks by “borrowing” bits from the host portion for the network portion.
8. Default and Custom IP Addressing (01.pdf)
- The default IPv4 addressing scheme is divided into classes (A, B, C, D, E) based on the first octet, determining the number of available networks and hosts.
- Class A (1-127): Large networks, many hosts. Default subnet mask: 255.0.0.0.
- Class B (128-191): Mid-sized networks, moderate hosts. Default subnet mask: 255.255.0.0.
- Class C (192-223): Small networks, fewer hosts. Default subnet mask: 255.255.255.0.
- Class D (224-239): Multicast.
- Class E (240-255): Experimental.
- “As we learned in previous modules the IPv4 addressing scheme is again 32 bits broken up into four octets and each octet can range from 0 to 255 Now the international standards organization I can which we’ve mentioned in a previous module is in control of how these IP addresses are leased and distributed out to individuals and companies around the world Now because of the limited amount of IP addresses the default IPv4 addressing scheme is designed and outlined which what are called classes and there are five of them that we need to know Now these classes are identified as A B C D and E And each class is designed to facilitate in the distribution of IP addresses for certain types of purposes.”
- Reserved and restricted IPv4 addresses:
- 127.0.0.1: Loopback address (localhost).
- Addresses with all zeros or all ones in the host portion (e.g., 0.0.0.0, 255.255.255.255) are typically not assignable (network address and broadcast address, respectively).
- 1.1.1.1: All hosts or “who is” address (generally unusable).
- Private IPv4 address ranges (not routable on the public internet):
- Class A: 10.0.0.0 – 10.255.255.255.
- Class B: 172.16.0.0 – 172.31.255.255.
- Class C: 192.168.0.0 – 192.168.255.255.
- “Private IP addresses are not routable This means that they are assigned for use on internal networks such as your home network or your office network When these addresses transmit data and it reaches a router the router is not going to uh route it outside of the network So these addresses can be used without needing to purchase or leasing an IP address from your ISP or internet service provider or governing entity.”
- IPv4 Formulas:
- Number of usable hosts per subnet: 2^x – 2 (where x is the number of host bits).
- Number of available subnets: 2^y – 2 (where y is the number of network bits borrowed).
- Default Gateway: The IP address of the router that a local device uses to communicate with networks outside its own subnet (often the internet).
- “The for any device that wants to connect to the internet has to go through what’s called a default gateway This is not a physical device This is set uh by our IP address settings It is basically the IP address of the device which is usually the router or the border router that’s connected directly to the to the internet.”
- Custom IP address schemes:
- VLSM (Variable Length Subnet Mask): Assigns each subnet its own customized subnet mask of varying length, allowing for more efficient IP address allocation.
- CIDR (Classless Inter-Domain Routing) / Supernetting / Classless Routing: Uses VLSM principles and represents networks using an IP address followed by a slash and a number indicating the number of network bits (e.g., 192.168.13.0/23). This notation simplifies subnetting and has led to classless address space on the internet.
9. Data Delivery Techniques and IPv6 (01.pdf)
- IPv6 is the successor to IPv4, offering a significantly larger address space (128-bit addresses).
- “The first major improvement that came with this new version is that there’s been an exponential increase in the number of possible addresses that are available Uh several other features were added to this addressing scheme as well such as security uh improved composition for what are called uniccast addresses uh header simplification and how they’re sent and uh hierarchal addressing for what some would suggest is easier routing And there’s also a support for what we call time sensitive traffic or traffic that needs to be received in a certain amount of time such as voice over IP and gaming And we’re going to look at all of this shortly. The IPv6 addressing scheme uses a 128 bit binary address This is different of course from IP version 4 which again uses a 32bit address So this means therefore that there are two to 128 power possible uh addresses as opposed to 2 to the 32 power with um IP address 4 And this means therefore that there are around 340 unicilian… addresses.”
- IPv6 addresses are written in hexadecimal format, with eight groups of four hexadecimal digits separated by colons.
- IPv6 address shortening rules (truncation):
- Leading zeros within a group can be omitted.
- One or more consecutive groups of zeros can be replaced with a double colon (::). This can only be done once in an address.
- IPv6 has a subnet size of /64 (the first 64 bits represent the network/subnet, the last 64 bits represent the host ID).
- Data delivery techniques involve connection-oriented (e.g., TCP, reliable, acknowledgment) and connectionless (e.g., UDP, faster, no guarantee) modes.
- Transmit types include unicast (one-to-one), multicast (one-to-many to interested hosts), and in IPv6, anycast (one-to-nearest of a group). Broadcast, present in IPv4, is not used in IPv6; multicast addresses fulfill similar functions.
- Data flow control mechanisms:
- Buffering: Temporary storage of data to manage rate mismatches and ensure consistency. Squelch signals can be sent if buffers are full.
- Data Windows: Amount of data sent before acknowledgment is required. Can be fixed length or sliding windows (adjusting size based on network conditions). Sliding windows help minimize congestion and maximize throughput.
- Error detection methods ensure data integrity during transmission (e.g., checksums).
10. IPv6 Address Types and Features (01.pdf)
- Main IPv6 address types:
- Global Unicast: Publicly routable addresses assigned by ISPs (range 2000::/3).
- Unique Local: Private addresses for internal networks (similar to IPv4 private addresses, deprecated FC00::/7).
- Link-Local: Non-routable addresses for communication within a single network link (FE80::/10). Automatically configured when IPv6 is enabled. Used for routing protocol communication and neighbor discovery.
- Multicast: One-to-many communication (FF00::/8). Replaces broadcast in IPv4. Used for duplicate address detection and neighbor discovery.
- Anycast: One-to-nearest of a group of interfaces (not explicitly detailed but mentioned).
- IPv6 features:
- Increased address space.
- Improved security features (IPSec integration).
- Simplified header format.
- Hierarchical addressing for efficient routing.
- Support for time-sensitive traffic (QoS).
- Plug-and-play capabilities with mobile devices.
- Stateless autoconfiguration (SLAAC).
- EUI-64 Addressing: A method for automatically generating the host portion of an IPv6 address using the 48-bit MAC address of the interface. This involves:
- Taking the 48-bit MAC address.
- Inserting FFFE in the middle (after the first 24 bits).
- Inverting the seventh bit (universal/local bit) of the first octet.
- Neighbor Discovery Protocol (NDP): Replaces ARP in IPv4. Used for:
- Router Solicitation (RS): Hosts ask for routers on the link.
- Router Advertisement (RA): Routers announce their presence and network prefixes.
- Neighbor Solicitation (NS): Hosts ask for the MAC address (link-layer address) of a neighbor or for duplicate address detection.
- Neighbor Advertisement (NA): Neighbors reply to NS messages or announce address changes.
- Duplicate Address Detection (DAD): Ensures IPv6 addresses are unique on the link using Neighbor Solicitation and Advertisement with multicast.
- DHCPv6: Used for stateful autoconfiguration, allocating IPv6 addresses, DNS server information, and other configuration parameters to hosts. Uses UDP ports 546 (client) and 547 (server).
- IPv6 Transition Mechanisms: Techniques to allow IPv6 hosts to communicate with IPv4 networks during the transition period, often involving tunneling IPv6 packets within IPv4 headers (e.g., ISATAP).
11. Static vs. Dynamic IP Addressing and DHCP (01.pdf)
- Static IP Addressing: Manually assigned IP address that does not change. Requires manual configuration of IP address, subnet mask, and default gateway on each device.
- Dynamic IP Addressing (DHCP): IP address is automatically assigned by a DHCP server and can change over time.
- “This is the protocol which assigns IP addresses And it does this first by assigning what’s called or defining rather what’s called the scope The scope are the ranges of all of the available IP address on the system that’s running the DHCP service And what this does is it takes one of the IP addresses from this scope and assigns it to a computer or a client.”
- DHCP Scope: The range of IP addresses available for assignment by the DHCP server. Exclusions can be configured for static IP addresses.
- DHCP Lease: The duration for which an IP address is assigned to a client. Clients must renew their lease periodically.
- Strengths and weaknesses:
- Static: Reliable for servers and devices needing consistent addresses, but requires more manual configuration and can lead to address conflicts if not managed carefully.
- Dynamic: Easier to manage for a large number of clients, reduces configuration overhead and potential for conflicts (if DHCP is properly configured), but IP addresses can change.
- APIPA (Automatic Private IP Addressing): A feature in Windows that automatically assigns an IP address in the 169.254.x.x range to a client if it cannot obtain an IP address from a DHCP server.
12. TCP/IP Tools and Commands (01.pdf)
- Essential TCP/IP tools for troubleshooting and network analysis:
- ping: Sends ICMP echo request packets to test connectivity to a destination host. Measures round-trip time (RTT) and packet loss.
- “The ping tool and the ping command are extremely useful when it comes to troubleshooting and testing connectivity Basically what the tool does is send a packet of information and that packet again is MP through a connection and waits to see if it receives some packets back.”
- traceroute (or tracert on Windows): Traces the path that packets take to a destination, showing the sequence of routers (hops) and the RTT at each hop. Uses ICMP time-exceeded messages.
- “It basically tells us the time it takes for a packet to travel between different routers and devices And we call this the amount of hops along the uh the network So it not only tests where connectivity might have been lost but it’s also going to test um the time that it takes to get from one end to the other end of the connection And it’s also going to also show us the number of hops between those computers.”
- Protocol Analyzer (Network Analyzer): Captures and analyzes network traffic (packets) in real-time or from a capture file. Provides detailed information about protocols, source/destination addresses, data content, etc. (e.g., Wireshark).
- “This is an essential tool when you’re running a network It basically gives you a readable report of virtually everything that’s being sent and transferred over your network So these analyzers will capture packets that are going through the network and put them into a buffer zone.”
- Port Scanner: Scans a network host for open TCP or UDP ports. Used for security assessments (identifying running services) or by attackers to find potential vulnerabilities (e.g., Nmap).
- “A port scanner does exactly what it sounds like It basically scans the network for open ports either for malicious or for safety reasons So uh it’s usually used by administrators to check the security of their system and make sure nothing’s left open Oppositely it can be used by attackers for their advantage.”
- nslookup: Queries DNS servers to obtain IP address information for a given domain name or vice versa. Useful for troubleshooting DNS-related issues. dig is a more advanced alternative on Unix/Linux systems.
- “It’s used to basically find out uh what the server and address information is for a domain that’s queried It’s mostly used to troubleshoot domain name service related items and you can also get information about a systems configuration.”
- arp: Displays and modifies the ARP cache, which maps IP addresses to MAC addresses on the local network.
- “It’s really used to find the media access control or MAC address or the physical address for an IP address or vice versa Remember this is the physical address It’s hardwired onto the device The MAC address is the system’s physical address and the IP address is the one again assigned by a server or manually assigned.”
- route: Displays and modifies the routing table of a host or router, showing the paths that network traffic will take. More commonly used on routers.
- “Finally the route command is extremely handy and can be used uh fairly often And it basically this shows you the routing table uh which is going to give you a list of all the routing entries.”
- ipconfig (Windows) / ifconfig (Linux/macOS): Displays and configures network interface parameters, including IP address, subnet mask, default gateway, and DNS server information.
13. Remote Networking and Access (01.pdf)
- Remote access allows users to connect to and use network resources from a distance.
- Key terms and concepts:
- VPN (Virtual Private Network): Extends a LAN across a wide area network (like the internet) by creating secure, encrypted tunnels. Provides confidentiality and integrity for remote connections.
- “In essence it extends a LAN or a local area network by adding the ability to have remote users connect to it The way it does this is by using what’s called tunneling It basically creates a tunnel in uh through the wide area network the internet that then I can connect to and through So all of my data is traveling through this tunnel between the server or the corporate office and the client computer This way I can make sure that no one outside the tunnel or anyone else on the network can get in and I can be sure that all of my data is kept secure This is why it’s called a virtual private network It’s virtual It’s not real It’s not physical It’s definitely private because the tunnel makes sure to keep everything out.”
- RADIUS (Remote Authentication Dial-In User Service): A centralized protocol for authentication, authorization, and accounting (AAA) of users connecting to a network remotely (e.g., VPN access).
- “What this does is it allows us to have centralized authorization authentication and accounting management for computers and users on a remote network In other words it allows me to have one server that’s going to be responsible and we’re going to call this the Radius server that’s responsible for making sure once a VPN is established that the person on the other end is actually someone who should be connecting to my network.”
- TACACS+ (Terminal Access Controller Access-Control System Plus): A Cisco-proprietary alternative to RADIUS that also provides centralized AAA services, offering more flexibility in protocol support and separating authorization and authentication.
- Diameter: Another AAA protocol, initially intended as a more robust replacement for RADIUS.
- Authentication: Verifying the identity of a user or device.
- Authorization: Determining what resources or actions an authenticated user is allowed to access or perform.
- Accounting: Tracking user activity and resource consumption.
14. IPSec and Security Policies (01.pdf)
- IPSec (IP Security): A suite of protocols and policies used to secure IP communications by providing confidentiality, integrity, and authentication at the IP layer.
- “They’re used to provide a secure channel of communication between two systems or more systems These systems can be within a local network within a wide area network or even across the internet.”
- Key protocols within IPSec:
- AH (Authentication Header): Provides data integrity and authentication of the sender but does not encrypt the data itself.
- ESP (Encapsulating Security Payload): Provides data confidentiality (encryption), integrity, and authentication. More commonly used than AH.
- Services provided by IPSec:
- Data verification (authentication).
- Protection from data tampering (integrity).
- Private transactions (confidentiality through encryption with ESP).
- IPSec Policies: Define how IPSec is implemented, including the protocols to be used, security algorithms, and key management. These policies are agreed upon by the communicating peers.
- “IPSec policies dictate the level of security that’s going to be applied to the communication between two or more hosts. These policies need to be configured on each of the systems that are going to be participating in the secure communication and they must agree upon the specific security parameters.”
- Security principles:
- CIA Triad (Confidentiality, Integrity, Availability): A fundamental model for information security. IPSec aims to enhance confidentiality and integrity while supporting availability by enabling secure communication channels.
Conclusion
The provided sources offer a comprehensive overview of essential networking concepts, ranging from fundamental data transmission mechanisms and addressing schemes (IPv4 and IPv6) to critical protocols, diagnostic tools, remote access technologies, and security principles like IPSec. Understanding these topics is crucial for anyone involved in network administration, security, or IT support. The emphasis on binary/decimal conversion, subnetting, IP address classes, well-known ports, and the functionality of key TCP/IP tools highlights their importance in network operations and troubleshooting. The introduction to IPv6, remote access methods (VPN, RADIUS), and IPSec provides a foundation for understanding modern network security and connectivity solutions.
Networking Concepts: Answering Frequently Asked Questions
Frequently Asked Questions about Networking Concepts
1. What happens when a datagram’s size exceeds the Maximum Transmission Unit (MTU) of a network device?
When a datagram is larger than a device’s MTU, the transmitting internet layer fragments the datagram into smaller, more manageable blocks. These fragments are then sent, and the receiving end’s internet layer reassembles them back into the original datagram during the reassembly process. The header of these fragmented datagrams includes flag bits: a reserved bit (always zero), the Don’t Fragment (DF) bit (on or off), and the More Fragments (MF) bit (on if more fragments are coming, off if it’s the last or only fragment).
2. What is an MTU black hole and how can it be detected?
An MTU black hole occurs when a datagram with an MTU greater than a receiving device’s MTU is sent. The receiving device should send an ICMP response indicating the MTU mismatch, but if this response is blocked (e.g., by a firewall), the sender doesn’t know the datagram was too large, and the data seems to disappear, hence the term “black hole.” One way to detect this is by using the ping utility with a specific syntax to set the MTU of the ICMP echo request. If pings at a certain MTU fail while those at a smaller MTU succeed, it indicates an MTU black hole.
3. How does the Network Interface Layer (Layer 1 of TCP/IP) function and what data type does it handle?
The Network Interface Layer is dedicated to the physical transfer of bits across the network medium. It corresponds to the Physical and Data Link Layers of the OSI model. The primary data type handled at this layer is called a “frame.” Major functions include switching operations (at the Data Link/Layer 2 level) that utilize MAC addresses for communication within a local network.
4. Explain the purpose and components of an Ethernet frame.
An Ethernet frame is the structure for transmitting data over an Ethernet network. It consists of several parts: * Preamble (7 bytes/56 bits): For synchronization and alerting the receiver. * Start of Frame Delimiter: Indicates the beginning of data. * Destination MAC Address (6 bytes/48 bits): The physical address of the intended recipient. * Source MAC Address (6 bytes/48 bits): The physical address of the sender. These components ensure that data is properly framed, addressed, and synchronized for transmission across the network.
5. Describe the Address Resolution Protocol (ARP) and its function in network communication.
ARP is a protocol used to map IP addresses to MAC addresses within a local area network. When a device wants to communicate with another device on the same network using its IP address, ARP is used to find the corresponding MAC address. The sending device broadcasts an ARP request containing the target IP address. The device with that IP address responds with an ARP reply containing its MAC address, allowing direct Layer 2 communication. Routers maintain ARP tables to cache these IP-to-MAC address mappings. RARP (Reverse ARP) performs the opposite function, mapping MAC addresses to IP addresses, though it is less commonly used today.
6. What are well-known, registered, and dynamic/private port ranges, and why are they important?
Network ports are logical endpoints for communication in a computer’s operating system, identified by numbers. The Internet Assigned Numbers Authority (IANA) regulates these assignments. The three ranges are: * Well-known ports (1-1023): Used by common services (e.g., HTTP on port 80, SMTP on port 25). Knowing these is crucial for network administration. * Registered ports (1024-49151): Reserved for applications that register with IANA. * Dynamic or private ports (49152-65535): Used for unregistered services, testing, and temporary connections. Understanding these ranges helps in network management, firewall configuration, and troubleshooting.
7. What are the key differences between IPv4 and IPv6 addressing schemes?
IPv6 is the successor to IPv4 and offers several improvements. IPv4 uses a 32-bit binary address, allowing for approximately 4.29 billion unique addresses. IPv6 uses a 128-bit binary address, providing a vastly larger address space (around 340 undecillion addresses). IPv6 also features improved security, simplified header format, hierarchical addressing for potentially easier routing, and support for time-sensitive traffic. Unlike IPv4, IPv6 has integrated subnetting (with a standard /64 subnet size) and does not rely on NAT as heavily due to the abundance of addresses. IPv6 addresses are written in hexadecimal format, separated by colons, and can be truncated using specific rules for readability.
8. Explain the concept of a default gateway and its role in network communication.
A default gateway is the IP address of a device (usually a router) on a local network that serves as an access point to other networks, including the internet. When a device on the local network needs to communicate with a device outside its own subnet, it sends the traffic to its configured default gateway. The default gateway then routes the traffic towards the destination network. For a device to connect to the internet, it typically needs to be configured with an IP address, a subnet mask, and the IP address of the default gateway.
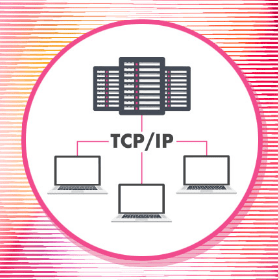
TCP/IP Model: Core Concepts of Network Communication
The TCP/IP model is a widely used networking model that allows for the conceptualization of how a computer network functions in maintaining hardware and protocol interoperability. It is also commonly called the DoD model because much of the research was funded by the Department of Defense. The TCP/IP model was permanently activated in 1983 and commercially marketed starting in 1985. It is now the preferred network standard for protocols. Understanding this model and how data flows within it is essential for all computers using the internet or most networks.
Key aspects of the TCP/IP model discussed in the sources include:
- Abstract Layers: Similar to the OSI model, the TCP/IP model is defined using abstract layers. However, the TCP/IP model consists of four layers:
- Network Interface Layer (Layer 1): This is the bottom layer and is dedicated to the actual transfer of bits across the network medium. It directly correlates to the physical and data link layers of the OSI model. The data type at this layer is called frames. Major functions include switching operations using MAC addresses. Protocols operating at this layer include point-to-point protocols, ISDN, and DSL. Protocol binding, the assignment of a protocol to a network interface card (NIC), occurs at this layer.
- Internet Layer (Layer 2): This layer corresponds directly to the network layer of the OSI model. The data terminology at this layer is a datagram or packet. This layer is responsible for routing to ensure the best path from source to destination and data addressing using the Internet Protocol (IP). Fragmentation of data occurs at this layer to accommodate Maximum Transmission Units (MTUs) of different network devices. The Internet Control Message Protocol (ICMP), used for diagnostic purposes like the ping utility, operates at this layer. The Address Resolution Protocol (ARP) and Reverse Address Resolution Protocol (RARP), used to map IP addresses to MAC addresses and vice versa, are also relevant here.
- Transport Layer (Layer 3): This layer corresponds directly to the transport layer of the OSI model. The main protocols at this layer are the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP). Data verification, error checking, and flow control are key functions of this layer. TCP is connection-oriented and guarantees delivery through sequence numbers and acknowledgements (ACK). It also handles segmentation of data. UDP is connectionless and provides a best-effort delivery without error checking.
- Application Layer (Layer 4): This is the topmost layer of the TCP/IP model. It encompasses the functions of the application, presentation, and session layers of the OSI model. Higher-level protocols like SMTP, FTP, and DNS reside here. This layer is responsible for process-to-process level data communication and manages network-related applications. It handles data encoding, encryption, compression, and session initiation and maintenance.
- Comparison with the OSI Model: The TCP/IP model was created before the OSI model. While both models use layers to describe communication systems, TCP/IP has four layers compared to OSI’s seven. Some layers have similar names, and there are correlations between the layers of the two models. For instance, the OSI’s application, presentation, and session layers map to the TCP/IP’s application layer; OSI’s transport layer maps to TCP/IP’s transport layer; OSI’s network layer maps to TCP/IP’s internet layer; and OSI’s data link and physical layers map to TCP/IP’s network interface layer. However, these correlations are not always precise due to the different designs and purposes of the two models. The OSI model aimed to simplify and standardize networking, while TCP/IP’s original purpose was to organize internet protocols into comprehensive groups based on their functions. Technicians often use the OSI model for troubleshooting and referencing networking devices, while the TCP/IP model is more representative of how communication and network protocols are defined and related.
- Data Encapsulation and De-encapsulation: The TCP/IP model outlines how data flows in a communication system by assigning specific functions to each layer. When sending data, each layer receives a data package from the layer above it and adds its own header (encapsulation) containing information for the corresponding layer on the receiving end. On the lowest layer, a footer (like the Frame Check Sequence – FCS) is also added for error detection. When receiving data, this process is reversed (de-encapsulation): each layer removes its header to perform its operations before passing the remaining data up the stack.
- Fragmentation: At the internet layer, the IP is responsible for fragmentation. This process breaks down large data units into smaller fragments if the data needs to pass through networks with smaller MTUs than the original data size. The MTU defines the largest size of data that can pass through a network device.
- Protocol Binding: This is the process where a network interface card is assigned a protocol. Multiple protocols can be bound to a single NIC, and the order of binding can be configured, although using a lesser protocol might result in slower speeds.
In summary, the TCP/IP model is a foundational concept in networking, providing a framework for understanding how data is transmitted across networks, particularly the internet. Its four-layer structure, along with the processes of encapsulation, de-encapsulation, and fragmentation, are crucial for ensuring reliable and efficient communication. While related to the OSI model, it has its own distinct characteristics and remains the dominant model in practice.
OSI Model vs. TCP/IP Model: A Comparative Overview
You’re asking for a discussion about the comparison between the OSI model and the TCP/IP model. As we discussed previously, both are networking models that utilize abstract layers to describe the functions of communication systems. However, there are several key differences and similarities between the two.
Here’s a comparison based on the sources:
- Number of Layers: The most obvious difference is the number of layers. The TCP/IP model has four layers, while the OSI model has seven layers.
- Purpose of Creation: The OSI model was created as an attempt to simplify and standardize networking. In contrast, TCP/IP’s original purpose was more about sorting out the internet protocols into comprehensive groups according to their functions and the scope of the network involved. The TCP/IP model is also known as the DoD model because its research was largely funded by the Department of Defense.
- Historical Context: The TCP/IP model was created before the OSI model. TCP/IP was permanently activated in 1983 and commercially marketed in 1985. The OSI model came later as an attempt to standardize the concepts that TCP/IP had already put into practice.
- Usage in Practice: While it’s important to be familiar with the OSI model, the TCP/IP model is considered one of the most common, if not the most widely used, networking model. It is the preferred network standard for protocols. However, it’s still more common to hear technicians and administrators use the OSI model when they are troubleshooting or referencing networking devices.
- Similarities in Layer Functions and Names: Both models use layers to describe the functions of these communication systems. Some layers even have similar names, such as the application layer and the transport layer in both models. Additionally, the network or internet layer in TCP/IP is similar to the network layer in OSI, and the network interface layer in TCP/IP is very much like the physical layer in OSI in some ways.
- Layer Correspondence: There are correlations between the layers of the two models:
- The application layer, presentation layer, and session layer of the OSI model correspond to the application layer of the TCP/IP stack.
- The transport layer of the OSI model corresponds directly to the transport layer of the TCP/IP model.
- The network layer of OSI corresponds to the internet layer of TCP/IP.
- The data link and physical layers of the OSI model correspond directly to the network interface layer of the TCP/IP.
- Precision of Correlations: It’s important to note that these correlations are not always precise and exact and are more like approximations because the two models were created differently and not necessarily with the other in mind.
- Interchangeable Layers: Both models have interchangeable network and transport layers. This means the functions performed at these layers can be conceptually swapped or understood in relation to each other across the two models.
In essence, while the OSI model provides a more detailed and theoretically comprehensive framework for understanding networking, the TCP/IP model is the practical model that underpins the internet and most modern networks. Understanding both models and their relationships is crucial for network technicians and administrators.
TCP/IP: Encapsulation and Fragmentation
Let’s discuss data encapsulation and fragmentation as they relate to the TCP/IP model, drawing on the information in the sources.
Data Encapsulation
Data encapsulation is the process by which each layer in the TCP/IP model adds its own packaging, called a header, to the data received from the layer above it when sending data. This header is used by the corresponding layer at the receiving end for specific purposes. The exact purpose of the header depends on the layer in question. The header is added to the beginning of the data so that it is the first thing received by the receiving layer. This allows each layer on the receiving end to remove the header, perform its operations, and then pass the remaining data up the TCP/IP model.
On the lowest layer, the network interface layer, a footer is also added to the frame. This footer adds supplemental information to assist the receiving end in ensuring that the data was received completely and undamaged. This footer is also called an FCS (Frame Check Sequence), which is used to check for errors in the received data.
The process of encapsulation goes down the TCP/IP stack: from the application layer to the transport layer, then to the internet layer, and finally to the network interface layer.
It’s important to understand how this works together to get a strong picture of the TCP/IP model and how data is transmitted. Just like the OSI model, the TCP/IP model uses encapsulation when data is going down the stack and de-encapsulation when data is traveling back up the stack at the receiving end. During de-encapsulation, the data is received at each layer, and the headers are removed to allow the data to perform the related tasks until it finally reaches the application layer.
Each layer is responsible for only the specific data defined at that layer. The layers receive data packages from the layer above when sending and the layer below when receiving.
Fragmentation
Fragmentation is a process that occurs at the internet layer (Layer 2 of the TCP/IP model). It is the division of a datagram into smaller blocks by the transmitting internet layer when the datagram is larger than the Maximum Transmission Unit (MTU) of a network device it needs to pass through. The MTU defines the largest size of data (in bytes) that can traverse a given network device, such as a router.
Network devices send and receive messages or responses to datagrams that are larger than their MTU. In these instances, the transmitting internet layer fragments the datagram and then tries to resend it in smaller, more manageable blocks. Once the data is fragmented enough to pass through the remaining devices, the receiving end’s internet layer then pieces together those fragments during the reassembly process.
In the header of fragmented datagrams, there is a specific field with three flag bits that are set aside for fragmentation control:
- A reserved bit that should always be zero.
- The Don’t Fragment (DF) bit. If this bit is off (zero), the datagram can be fragmented. If it’s on, the datagram should not be fragmented.
- The More Fragments (MF) bit. When this bit is on, it indicates that there are more fragments to follow. When it’s off, it means that it’s the last fragment or that there were no fragments to begin with.
Fragmentation is crucial because data often needs to pass through networks with MTUs that are smaller than the MTU of the originating device. By fragmenting the data into smaller units, the internet layer ensures that the data can be transmitted across such networks.
A networking problem related to MTUs and fragmentation is the MTU black hole, where a datagram is sent with an MTU greater than the receiving device’s MTU. The destination device should send an ICMP response notifying the sender of the MTU mismatch, but if this response is blocked (e.g., by a firewall), the sender never knows to reduce the MTU or fragment the data, leading to the disappearance of the datagram.
Relationship between Encapsulation and Fragmentation
Fragmentation occurs at the internet layer, which is responsible for routing and addressing. Before the internet layer processes the data for fragmentation (if necessary), the data has already been encapsulated by the application layer (which might perform encoding, encryption, and compression) and the transport layer (which adds segment headers with information for reliable delivery and flow control, in the case of TCP). The datagram that the internet layer receives already contains these encapsulated headers and the original application data. When fragmentation happens, the internet layer takes this datagram and breaks it into smaller fragments, adding its own IP header to each fragment. This IP header includes the necessary information for reassembly at the destination, such as identification fields and the MF and DF flags.
In essence, encapsulation prepares the data with headers relevant to each layer’s function as it moves down the stack, and fragmentation is a process at the internet layer that might further divide the encapsulated data to ensure it can be physically transmitted across different network segments with varying MTU restrictions.
TCP/IP Model: Understanding the Four Layers
Let’s discuss the four layers of the TCP/IP model as outlined in the sources. The TCP/IP model is a widely used networking model that conceptualizes how a computer network functions in maintaining hardware and protocol interoperability. It consists of four abstract layers. Understanding these layers and how data flows through them is essential for anyone working with computer networks and the internet.
Here’s a breakdown of each layer:
- Application Layer (Topmost Layer)
- Purpose and Functions: The application layer in the TCP/IP model is where high-level protocols operate. These protocols, such as SMTP (Simple Mail Transfer Protocol), FTP (File Transfer Protocol), and others, are not necessarily concerned with how the data arrives at its destination but simply that it arrives.
- Relationship to OSI Model: The TCP/IP application layer provides the functions that relate to the presentation and the session layers of the OSI model. Essentially, everything in the OSI model that fell into the application, presentation, and session layers is handled within the application layer of the TCP/IP stack. This is often done through the use of libraries which contain behavioral implementations that can be used by unrelated services.
- Key Functions: The application layer encodes data, performs necessary encryption and compression, and manages the initiation and maintenance of connections or sessions. It is responsible for process-to-process level data communication, meaning it defines what type of application can be utilized depending on the protocol. For example, SMTP specifies outgoing mail communication, and IMAP specifies incoming mail communication. Only network-related applications are managed at this layer.
- Example Protocols: Examples of protocols found at this layer include SMTP, FTP, TFTP (Trivial FTP), DNS (Domain Name Service), SNMP (Simple Network Management Protocol), BOOTP (Bootstrap Protocol), HTTP (Hypertext Transfer Protocol), HTTPS (Secure HTTP), RDP (Remote Desktop Protocol), POP3 (Post Office Protocol version 3), IMAP (Internet Message Access Protocol), and NNTP (Network News Transfer Protocol).
- Data Terminology: At this layer, we are generally talking about data.
- Transport Layer (Third Layer)
- Purpose and Functions: The transport layer is primarily responsible for data verification, error checking, and flow control. It utilizes two main protocols: TCP (Transmission Control Protocol) and UDP (User Datagram Protocol).
- Relationship to OSI Model: The transport layer of the OSI model corresponds directly to the transport layer of the TCP/IP model.
- Key Protocols and Characteristics:TCP: Connection-oriented, providing guaranteed delivery of data through mechanisms like sequence numbers and acknowledgements (ACK messages). If an acknowledgement is not received, TCP will retransmit the lost segment. TCP also handles data flow control to prevent faster devices from overwhelming slower ones and performs segmentation, breaking down application data into smaller segments for transmission. A connection using TCP requires the establishment of a session between port numbers, forming a socket (IP address and port number combination).
- UDP: Connectionless, offering a best-effort delivery without guaranteed delivery or error checking beyond a checksum for data integrity. UDP is faster than TCP as it doesn’t have the overhead of connection establishment and reliability mechanisms. It is often used for applications where speed is critical and occasional data loss is acceptable, such as VoIP (Voice over IP) and online gaming. UDP also uses port numbers to direct traffic to specific applications.
- Data Terminology: At this layer, the data from the application layer is broken into segments (for TCP) or datagrams (for UDP).
- Internet Layer (Second Layer)
- Purpose and Functions: The internet layer is primarily responsible for routing data across networks, ensuring the best path from source to destination, and data addressing using the Internet Protocol (IP).
- Relationship to OSI Model: The internet layer of the TCP/IP model corresponds directly to the network layer of the OSI model. The term “internet” in this context refers to inter-networking. Layer 3 devices in the OSI model, routers, operate at this layer.
- Key Protocols and Characteristics: The main protocol at this layer is IP, which is connectionless and focuses on source-to-destination navigation (routing), host identification (using IP addresses), and data delivery solely based on the IP address. IP is also responsible for fragmentation of data packets (datagrams) when they exceed the Maximum Transmission Unit (MTU) of a network device. The internet layer also involves protocols like ICMP (Internet Control Message Protocol), used for diagnostic and testing purposes (like the ping utility), and ARP (Address Resolution Protocol) and RARP (Reverse Address Resolution Protocol), which are used to map IP addresses to MAC addresses and vice versa, crucial for routing within a local network. IGMP (Internet Group Management Protocol) is used for establishing memberships for multicast groups.
- Data Terminology: The data unit at this layer is called a datagram or packet.
- Network Interface Layer (Bottom Layer)
- Purpose and Functions: This layer is completely dedicated to the actual transfer of bits across the network medium. It handles the physical connection to the network and the transmission of data frames.
- Relationship to OSI Model: The network interface layer of the TCP/IP model directly correlates to the physical and the data link layer of the OSI model.
- Key Functions and Concepts: This layer is responsible for switching operations (like those occurring at Layer 2 of the OSI model) and deals with MAC addresses (Media Access Control addresses), which are 48-bit hexadecimal universally unique identifiers used for local network communication. The Ethernet frame is a key data structure at this layer, consisting of a preamble, start of frame delimiter, destination and source MAC addresses, frame type, data field (with a maximum size of 1500 bytes), and a frame check sequence (FCS) for error detection using CRC (Cyclic Redundancy Check). This layer is also responsible for network access control, and protocols like Point-to-Point Protocol (PPP), ISDN, and DSL operate at this level. Protocol binding, the association of a protocol to a specific network interface card (NIC), also occurs at this layer.
- Data Terminology: The data unit at this layer is called a frame.
Understanding these four layers and their respective functions and protocols is fundamental to comprehending how data communication works within the TCP/IP model and across the internet. The model provides a crucial framework for network technicians and administrators to understand network infrastructure, design, and troubleshooting.
Protocol Binding and MTU in Networking
Let’s discuss protocol binding and MTU (Maximum Transmission Unit) as described in the sources.
Protocol Binding
- Definition: Protocol binding is when a network interface card (NIC) receives an assigned protocol. It’s considered the process of binding that protocol to that NIC.
- Importance: It is very important to have protocols bound to the NIC because it’s how the data is passed down from one layer of the TCP/IP model to the next. Without the correct protocols bound to the NIC, the computer wouldn’t know how to handle network communication.
- Multiple Bindings: A single network interface card can have multiple protocols bound to it.
- Configuration: You can typically see and configure protocol bindings in your network connection properties or adapter settings, such as in Windows, where you can view IPv4 and IPv6 configurations.
- Order of Binding: You can often change the order of binding of protocols. This can potentially speed up your network if you prioritize the protocol you use most frequently, as the system will check the protocols in the order they are listed. The first protocol found to have a matching active protocol on the receiving end will be used. However, using a lesser protocol higher in the binding order might result in slower speeds.
- Location of Configuration: The graphical interface or properties menu for your network interface card is where you configure protocol binding, along with other settings like TCP/IP, DNS server assignment, and DHCP.
MTU (Maximum Transmission Unit)
- Definition: MTU is the term that defines the largest size of increment of data in bytes that can pass through a given network device such as a router.
- Importance for Fragmentation: Understanding MTU is crucial because data often needs to pass through networks with MTUs that are less than the MTU listed on the transmitting device.
- Fragmentation Process: When a datagram is larger than the MTU of a device, the transmitting internet layer (Layer 2 in the TCP/IP model) fragments the data or the datagram into smaller, more manageable blocks. These fragments are then sent.
- Reassembly: The receiving end’s internet layer is responsible for piecing together these fragments during the reassembly process.
- Fragmentation Control Bits: The header of fragmented datagrams contains specific flag bits:
- Reserved bit: Always zero.
- Don’t Fragment (DF) bit: Indicates whether the datagram should be fragmented (off/zero) or not (on).
- More Fragments (MF) bit: When on, it signifies that more fragments are on the way. When off, it indicates the last fragment or that there were no fragments.
- MTU Black Hole: A black hole router is a situation where a datagram is sent with an MTU greater than the MTU of the receiving device. Ideally, the destination device should send an ICMP response notifying the sender of the MTU mismatch. However, if this ICMP response is blocked (e.g., by a firewall), the sender doesn’t know about the problem, and the datagram is effectively lost, disappearing into a “black hole”.
- Detection of MTU Black Hole: One way to detect an MTU black hole is by using the ping utility with a syntax that allows you to specify the MTU of the ICMP echo request. By varying the MTU size in the ping requests, you can identify if responses are not received at certain MTU sizes, indicating a potential black hole.
- TCP’s Role with MTU: TCP attempts to alleviate MTU mismatches at the data link layer by establishing maximum segment sizes (MSS) that can be accepted by TCP. This can help reduce the occurrence of MTU black holes.
In summary, protocol binding ensures that the network interface card knows which communication rules (protocols) to use, while MTU is a limitation on the size of data packets that can be transmitted on a network path. When the MTU is too small for a datagram, fragmentation occurs at the internet layer to break down the data. Issues can arise with MTU black holes if feedback about MTU limitations is blocked, leading to lost data. Understanding both concepts is crucial for effective network operation and troubleshooting.
The Original Text
network infrastructure and design network models the TCPIP model whereas in the previous module we talked about the OSI model a mostly theoretical model that’s in use in computer networks in this module we’re going to talk about perhaps what is considered to be one of the most common or at least the most widely used model the TCP IP model while it’s important that we memorize and familiarize ourselves with the OSI model it’s also really important that we understand this TCPI IP model and the differences between it and the OSI model As technicians and administrators it’s really important that we’re familiar with each layer as well as how data transfers between all of these layers and how all the protocols that are used in TCBIP relate to one another and in the layers So the objectives of this module are first to explain the purpose and depth of the TCPIP model and to compare it in some ways with the OSI model We’re also going to talk about what data encapsulation and fragmentation are These are really key to how large amounts of data are able to be transmitted and transferred over the internet the largest network in the world And then we’re going to talk about the four layers of the TCP IP model beginning with the fourth one and then the third the second and the first Finally we’re going to talk about protocol binding and something called an MTU black hole that doesn’t really occur much anymore but that Network Plus wants you to be familiar with So as mentioned before the TCPIP model is perhaps the most widely known or used networking model It’s uh another networking model that’s most commonly defined using ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab ab abstract layers just like we had with the OSI model Now the entire purpose of this model is to allow for conceptualization of how a computer network functions in maintaining hardware and protocol interoperability Also it’s commonly called the DoD model for the Department of Defense which funded uh much of the research that went into it Uh TCPIP was permanently uh uh activated in 1983 and it’s been in use uh just about ever since Now it wasn’t until 1985 that this model was actually commercially marketed uh but it is now the preferred me network standard uh for protocols and so on Now this means that using these four layers on this model the bottom being the network interface layer the internet layer the transport layer and then finally the application layer and if you know or remember the OSI model you’ll see that there is some resemblance uh these understanding these this model and understanding how data flows is actually how the entire world is allowed to communicate and connect to the network so this is necessary for every computer in the world that is currently using the internet and for the most part that’s on any network We might find other smaller lesserk known protocols that do operate outside of this but I think you would be hardpressed in today’s day and age to see that So technicians and engineers will probably sit and talk about technologies implementation of these two models for hours on end Uh and the reason is because there’s quite a bit of history and brilliant thinking that went into the creation of both of them The TCPIP model was in fact created before the OSI model Uh and it still makes it easier to represent how communication and network related protocols are defined and relate to one another However it’s still more common to hear technicians and administrators use the OSI model when they’re troubleshooting or referencing networking devices And there are many similarities between the two models The first similarity is the obvious use of the layers to describe the functions of these communication systems Although in TCP IP we have four whereas in OSI as you recall we have seven Some of them even have similar names as you can see uh from application and transport And then we see network or internet and network interface which is very much like physical In some ways some people consider the TCP IP model to be a smaller version of the OSI model However this leads to some misconceptions about the position of relationships of certain protocols within the OSI model Because these are very two very different designs and they have different purposes there are some recognizable similarities but they’re still at at their core different So the purpose of this OSI model was an attempt to simplify and standardize networking TCPIP’s original purpose as opposed to the OSI is more attempting to sort of uh sort out the internet protocols into comprehensive groups according to their functions of the scope and the sort of network that’s involved Now one of the similarities between the two models is they both have interchangeable network and transport layers Uh also each layer of the OSI model directly correlates with the TCP IP model And here you can see the application layer the presentation layer and the session layer of the OSI model correspond to what we know as the application layer of the TCP IP stack This means that everything in the OSI model that fell into application presentation and session are actually done in the application support block Next the transport layer of the OSI model corresponds directly to the transport layer of the TCP IP model the network layer of OSI with the internet layer of TCP IP and that is easy to remember since internet is really short for like inter networking and the data link and physical layers of the OSI model correspond directly to the network interface layer of the TCP IP Now some of these correlations it should be mentioned aren’t precise and exact they’re sort of um approximations and that’s because they are two very different models and therefore they were created differently and weren’t necessarily created with the one or the other in mind That being said TCP IP and OSI were built with knowledge of one another and so we do see this overlap Now the TCPIP model outlines and defines the methods data is going to flow in commu in a communication system It does this by assigning each layer in the stack specific functions to perform on the data And ultimately each layer is completely independent of all the other layers and more or less is unaware of the other layers For instance the topmost layer the application layer is going to perform its operations if the processes on the communicating systems are directly connected to each other by some sort of information pipe The operations that allow for the next layer the transport layer to transmit data between the host computers is actually found in the protocols of lower lay layers And from there on each data uh layer will complete its specified actions to the data and then encapsulate the data where it’s then passed down the stack in the opposite direction when data is traveling back up the stack and we saw the same thing with OSI model uh the data is then deenapsulated so when it’s going down we call that being encapsulated and when it’s going back up we call it deenapsulated So we really need to understand how all of this works together in order to uh get a really strong picture of uh uh TCP IP and be able to speak about the layers in general So let’s talk about encapsulation Each layer is responsible for only the specific data defined at that layer as we’ve said Now these layers are going to receive the data package from the layer above it when sending and the layer below it when receiving This makes sense If I’m receiving data it’s going up So the data is coming from below And if I’m sending it’s going down from the application down to the networking interface Now when it receives this package each layer is going to add its own packaging which is called a header This header is used by the corresponding layer at the receiving side for specific purposes The exact purpose is really going to depend on the layer in question But this header is going to be added to the beginning of the data so that it is the first thing received by the receiving layer That way each layer on the receiving end can then remove that header perform its operations and then pass the remaining data up the stack up the TCP IP model On the lowest layer a footer is also going to be added And this is going to add uh to the frame by adding more supplemental information This extra data at the end of the data package is going to assist the receiving end on ensuring that the data was received completely and undamaged This footer is also what’s called an FCS or a frame check sequence And as the name implies it is going to check to make sure the data was received correctly Now on the receiving end this process is reversed by what’s called de-incapsulation In other words the data is received at each layer and the headers are removed to allow the data to perform the related tasks where finally the data is received by the application uh the application layer and then the resulting data is delivered to whatever the requested application was Now just like with the OSI model which we’ll talk about later this application layer doesn’t mean the actual application itself It’s simply the layer that provides access to the information from an application Now just like the OSI model there are a few pneummonic devices that can be used to help in remembering these layers in order and the one that I use the most uh going from the top down is called all things in networking again that’s application all transport things internet in network interface networking so now we have a better understanding of how the data is going to proceed from layer to layer through encapsulation going down from application to transport to internet to network interface right And then through deinter de- enapsulation which goes the opposite way Let’s take a closer look at these layers Starting with the topmost layer the application layer So here on the application layer much like the application layer of the OSI model we find what’s considered the highest level protocols Higher level meaning these protocols such as SMTP FTP and so on These protocols are not necessarily concerned with the method by which the data arrives at its destination but simply that it just arrives period Here in the application layer we also provide the functions that relate to the presentation and the session layers of the OSI model As we’ve already pointed out it does this typically through the use of what are called libraries which are collections of uh behavioral implementations that can be utilized and called upon by services that are unrelated So this means that the application layer of the TCP IP model encodes the data and performs any encryption and compression that’s necessary as well as initiating and maintaining the the connection or the session As we can see here these are just some of the protocols that we find at the application layer We can also further group some of these applications based on the specific type of function that they provide Uh for instance if we’re looking at protocols that are dedicated to transferring files such as FTP or TFTP which if you recall is the trivial FTP Then there are also protocols that can be categorized by supporting services So some of those are going to be for instance DNS the domain name service and SNMP which is for management purposes or even bootp or the bootstrap protocol Now just like the OSI models application layer this TCP IP application layer is responsible for processtorocess level data communication This means that the application itself doesn’t necessarily reside on this layer What it more means is that it defines what the application or what type of application can be utilized depending on the protocol So for example SMTP specifies that outgoing mail communication with the mail or exchange server and IMAP specifies the incoming mail communication with the mail server Also remember that only those applications that are network relatable are going to be managed at this layer not necessarily all application So this layer’s role is more towards software applications and protocols and their interaction with the user It’s not as concerned with the formatting or transmitting the data across the media For that we have to move lower down into the model and get to the transport layer Now on the transport layer of the TCP IP model we have two main protocols that we need to be familiar with First we have the transmission control protocol or TCP and the second is the user datagramgram protocol or UDP Let me just write those out here so that you can um see what these stand for again Now on this layer three things are going on Uh data verification error checking and flow control Now our two heavyhitting protocols are done in very different ways So TCPIP as we’ve talked about in the past is what we call connection oriented which means there’s a guaranteed delivery whereas UDP is connectionless which means it’s just a best effort delivery UDP doesn’t have any means of error checking That’s one of TCP’s areas of expertise So to put TCP and UDP in perspective I’ve always thought about it as if um say a grade school teacher needs to send a note to a student’s parent because the student hadn’t turned in their homework for more than a week Now the teacher can send the note one of two ways The first is through UDP or the uninterested doubtful pre-teen Now this UDP is certainly going to make it home as quickly as possible but whether the message gets sent to the parent or not really isn’t UDP’s biggest concern getting there quickly is so UDP is going to have you that quick but not necessarily guaranteed Now meanwhile the other method TCP or teacher calls parent this is the way the teacher has a guaranteed delivery of the message but if parents aren’t home the message cannot be delivered or something happens during the communication process TCP will wait and attempt to send the message again So whereas TCP uh UDP is quick TCP is guaranteed and so that’s sort of the give and take there Now while our story is a generalization it really touches on the two most important characteristics of these protocols Now there are a few other uh specifics about TCP that are are really worth mentioning Firstly and most importantly we have reliability Like we just mentioned how it accomplishes this is TCP assigns a sequence numbers to each segment of data and the receiving end looks for these sequence numbers and sends what’s called an act or acknowledgement message which is something important that you do want to um uh be familiar with and you might also see that as a sin act which is the synchronization and that act message is sent when the data is successfully received Now if the sending transport layer doesn’t receive the accurate acknowledgement message then it’s going to retransmit the lost segment Secondly we have data flow control which is we’ve already mentioned This is important in as network devices are not always going to operate at the same speeds and without flow control slower devices might overrun by might be overrun with data causing network downtime Thirdly we have something called segmentation And segmentation occurs at this layer taking the tedious task away from the application layer of sectioning the data into pieces or segments These segments can then get sent to the next layer below to be prepared for transmitt across the media So the final consideration for TCP is in order for an application to be able to utilize this protocol a connection between port numbers has to be established The devices try to create this session using a combination of an IP address and a port number Now this combination is called a socket In the future modules we’re going to look at at referencing TCP and UDP as well as going a bit more further into explaining how they function and interact with different protocols But what you see here is the IP address on a specific port number So we know based on this port number what the connection is trying to attempt and whether or not it’s TCP or UDP we know whether it’s connection oriented or connectionless The internet layer of the TCP IP model corresponds directly to the network layer of the OSI model Now the data terminology on this layer as I think we discussed when we talked about the OSI model is a datagramgram Now as the internet layer relates directly to the network layer which if you recall was layer three we can a little more easily understand a few things that happen on this layer First it tells us that this layer is responsible for routing If you recall layer 3 devices for OSI are routers This means that it ensures the typically fastest and best path from the source to the destination This layer is also responsible for data addressing And if you recall with data addressing we’re dealing with the second part of TCP IP which is the internet protocol aptly named is since it is on the internet layer Now the internet protocol is responsible for a couple main functions The first of those functions is what we call fragmentation It’s important for us to understand something called MTUs which are maximum transmission units so that we know why fragmentation has to occur Now the MTU is the term as the name implies that’s used to define the largest size of increment of data in bytes that can pass through the given network device such as a router Now often data is going to need to pass through networks with MTUs that are less than the MTU listed on that device uh generally even uh not just match two but the the lower it is the more it’s preferred because then we can make sure that it’s not going to have a problem So network devices are going to send and receive messages or responses to datagramgrams that are larger than the devices MTU In these instances when there is a datagramgram that’s larger than the MTU of a device the transmitting internet layer fragments the data or the datagramgram and then tries to resend it in smaller and more easily manageable blocks So once the data is fragmented enough to pass through the remaining devices the receiving ends internet layer then pieces together those fragments during the reassembly process Now in the header of those fragmented datagramgrams if we go back just a bit you see right here the header there’s a specific field that’s set aside for what we call three flag bits The first flag bit is reserved and should always be zero The second is the don’t fragment or the DF bit Now either this bit is off or zero which means fragment this datagram or on meaning don’t fragment this datagram The third flag bit is the more fragments bit MF And when this is on it means that there are more fragments on the way And finally when the MF flag is off it means there are no more fragments to be sent as you can see right here And that there were never any fragments to send So as we see here our initial DI datagramgram that we wanted to transmit had uh an MTU that was too large to send It was 2500 and it was too large therefore to go through router B And so then we fragmented this datagramgram and added those bits to the headers of the fragments So that’s how this all works and that’s why fragmenting is so important Now let’s take a look at a networking problem that used to plague network engineers and technicians that has to do with MTUs for some time This is also something that’s specifically called for on the network plus exam Now a black hole router is the name given to a situation where a datagramgram is sent with an MTU that’s greater than the MTU of the receiving device as we can see here Now when the destination device is unable to receive the IP datagramgram it’s supposed to send a specific ICMP response that notifies the transmitting station that there’s an MTU mismatch This can be due to a variety of reasons one of which could be as simple as a firewall that’s blocking the MP response And by the way when we talk about ICMP we’re really talking about the ping utility as well Now in these cases this is called a black hole because of the disappearance of datagramgrams Basically as you can see I’m sending the data The data gets here The device the router here says “Wait a minute I can’t fit that 2500 MTU through my 1500.” Sends a response but for some reason the response hits this firewall and doesn’t make it back to the router And so the data is lost into this black hole Now this is called a black hole because this datagramgram disappears as if it were sucked into a black hole Now there are some ways to detect or find this MTU black hole And one of the best ways is to use the ping utility and specify a syntax that sets the MTU of the ICMP echo request meaning you tell it I want to ping with this much of an MTU And so then we can see if the ping’s not coming back if it’s coming back at one MTU and not another then we know oh this is what’s happening right here And we can determine uh where the black hole is specifically occurring Now on the bottom of the TCP IP stack is the network interface layer Now this layer is completely dedicated to the actual transfer of bits across the network medium The network interface layer of the TCP IP model directly correlates to the physical and the data link layer of the OSI model Now the data type we’re going to be talking about on this layer are what we call frames as opposed to datagramgrams Now the major functions that are performed on this layer on the data link of the OSI model are also occurring at this layer So um we’re really talking about switching operations that occur on layer 2 which again is that data link layer And so this is where we see switches operating which means that we’re really dealing with MAC addresses Okay Now a MAC address again is a 48 bit hexadesimal universally unique identifier that’s broken up into several parts The first part of it is what we call the OUI or the organizational unique identifier This basically says what company is uh sending out this device And then we have the second part which is the nick specific And then we have the second part which is specific to that device itself So this is the manufacturer and this is for the device You can literally go online search for this part of the MAC address and it’ll tell you what company uh is creating this device Now the easiest way to find the MAC address in a Windows PC is by opening up the command prompt and using IP config all which we’ve talked about in A+ This brings up the internet protocol information the IP address and it also brings up the MAC address or the physical address that’s assigned to your nick So now that we’ve covered the MAC address is it’s really important to understand the parts of an Ethernet frame And remember we’re talking about frames at this uh juncture So the preamble of an Ethernet frame is made up of seven bytes or 56 bits And this serves as synchronization and gives the receiving station a heads up to standby and look out for a signal that’s coming The next part is what we call the start of frame delimiter The only purpose of this is to indicate the start of data The next two parts are the source and destination MAC addresses So the Ethernet frame again this is everything that’s going over this Ethernet uh over the network We have the preamble that says “Hey pay attention now.” This that says “Now I’m giving you some data.” And then we have the destination and the source MAC addresses So that way we know where it’s coming from who it’s going to And this takes up 96 bits or 12 bytes because remember this is 48 bits right here So if we double that that’s going to be 96 And then the next type is what’s called the frame type This is two uh uh bytes that contain either the client protocol information or the number of bytes that are found in the data field which happen to be the next part of the frame which is the data This field is going to be a certain number of bytes and the amount of data is going to change with any given transmission The maximum amount of data allowed in this field is 1,500 bytes We can’t have more than that Now if this field is any less than 46 bytes then we have to actually have something called a pad which is actually just going to be used to fill in the rest of the data And the final part of this Ethernet frame is called the FCS or the frame check sequence and this is used for cyclic redundancy check which is also called CRC This basically allows us to make sure that there are no errors in the data Now similar to the way that a an algorithm is going to be used to ensure integrity of data the CRC uses a mathematical algorithm which sometimes we’re going to refer to as hashing which we’ll talk a lot more about when we get to security plus that’s made before the data is sent and then it is checked when it gets there That way we can compare the two results bit for bit and if the two numbers don’t match then we know the frame needs to be discarded we assume there’s been a transmission error or that there was a data collision of some sort and then we ask the data to be resent Now this layer by the way this network interface layer is also responsible for the network access control and some of the protocols that operate on this are what are called uh pointtooint protocols ISDN which is a uh which we’ve talked about also a type of um network and also DSL So these are some of the things that exist at this and this makes sense because again we’re dealing with the physical bits bytes of data So now that we’ve taken a look at each of the layers in the TCP IP model there’s still a couple things that we still need to define Now we’ve discussed how some of the protocols that we’ve seen uh relate to the OSI model as well as the TCP IP model And we found that some of the protocols function much more smoothly when they’re put into the context of an outline of one of these models So the next definition I want to make sure to cover is something called protocol binding This is when a network interface card receives an assigned protocol It’s considered binding that protocol to that nick So just as we learned how the data is going to be passed down from one layer to the next It’s very important that we have these protocols bound to the nick We can have multiple protocols actually bound to one network interface card Now of course the most easily recognized uh we can most easily recognize these when we’re looking at the IPv4 and IPv6 configurations in our network connection properties or adapter settings in Windows For instance you use a specific protocol more than others and you’re confident in the stability of the connection you can change the order of binding to potentially speed up your network since what it basically does is it’s going to give a list of each protocol that exists and it’s going to hit each protocol one after the other So if there’s one that you use more you can set that at the top so it doesn’t have as far to go So as we can see here we have several default protocols um and they’re going to be tested in order uh for that available connection And the first protocol that’s found to have a matching active protocol on the receiving end is going to be the one we use Now the while this might sound like a pretty decent method of doing things it also opens your computer up to utilizing a lesser protocol which is potentially going to give you a slower speed So the graphical interface or properties menu for your um uh network interface card is where you’re going to be able to configure all of this stuff stuff such as uh TCP IP um DNS server assignment DHCP and so on and so forth So after all of this it’s really important to understand that all of this organizing categorizing defining of these protocols the assigning of rules and roles all of this the the internet didn’t just happen overnight It’s not even necessarily the way we did it on purpose These standards and these models are going to continue to expand and change and eventually we might even have a brand new model that we’re going to have to learn about But in the meantime these models are here to stay and they’re going to remain really important And especially uh in the future you have to understand the historical roots of the network so you can be able to define not only how to go forward in the future but also how to you know prepare yourself for a network plus exam So let’s just go back over everything we’ve talked about one last time We covered in great a lot of stuff here right First we explained the purpose of the TCPIP model and we compared the TCPIP model with the OSI model Remembering that the top three layers if we look at this if we do the 3 2 1 and then we look at 76 54 right two in one physical and data link are going to go straight over here to uh that physical layer one of the TCP IP model Then the network layer is going to correspond directly to the internet layer The transport layers are going to be the same and session presentation and application all go over to the presentation layer in TCP IP We also talked about defining data encapsulation and we walked through how fragmentation works on the internet layer And the reason we need to do that is because of the maximum transmission unit Finally we talked about the fourth third second and first layers of the T TCP IP model And on each model we outlined some of the important aspects of each layer such as the um uh application layer which again is the way that the application is going to process all of this information the transport layer which is in charge of reliability and it is where TCP which is connection oriented or UDP which is connectionless live and this is also going to deal with flow control and also segmentation We looked at uh layer two as well which is the internet layer and the fragmentation that happens there and network one the network interface layer which is equivalent to all that physical stuff that we’ve talked about We also looked at how the terminology changes Remember on layer four we’re talking about data On layer three we’re dealing with segments on layer two we’re dealing with datagramgrams also called packets And we broke down then on layer 1 frames and an Ethernet frame and all the information that goes into that Finally we defined what an MTU black hole was And we finished off everything by talking about protocol binding which is binding certain protocols to specific nicks and in a in a delineated order IP addresses and conversion So welcome to this module We’re going to cover IP addresses and conversions uh and in some of the previous modules we talked about a lot of the technologies and theories and protocols that make up computer networks and so here we’re going to discuss some of the more important aspects of networking specifically the IP address So this module is going to begin by introducing us to some of the specific protocols that are found within the TCPIP protocol suite uh that you need to know about for the network plus exam And these are TCP and IP in a little more depth We mentioned them briefly when we talked about the TCP IP uh model And then we’re going to describe UDP which is a connectionless uh protocol Then we’re going to look at ARP and RARP Uh two versions that allow us to basically um or two protocols rather that basically allow us to map MAC addresses to IP addresses and which are basically responsible for routing in general And after that we’re going to look at two management protocols One called ICMP which I introduced to you in previous modules and I said it was related to the ping utility We’re going to learn a little more about that and then IGMP uh which is uh slightly different has to do more with multiccasting and uniccasting And then we’re going to continue by outlining uh IP packet delivery processes and we’re going to finish off the module with a bit of an introduction into binary and decimal conversions uh so that later on we can talk a little more in depth about IP addressing and um how something called subnetting works which is going to require us to understand the difference between these two ways of writing our our um numbers and after we have covered all these topics we’re going to have a fundamental understanding of IP that’s going to prepare us for some of the more indepth topics as I just mentioned in the following modules so uh let’s begin by taking a look at two of the most important protocols that make up the suite TCP and IP Now in previous chapters we briefly described these two but we still need to take a closer look at them to asssure that we have a complete understanding of the many different protocols that are found in our protocol suite So first for those applications and instances that depend on data to be reliable in terms of delivery and integrity the transmission control protocol or TCP and I’m just going to write out transmission control protocol is a really dependable protocol and provides a number of features First it guarantees that data delivery and besides um guaranteeing that delivery it also has a certain amount of reliability It also offers flow control which as we’ve mentioned in the past assists a sending station in making sure it doesn’t send data faster than the receiver can handle This function also is going to assist in the reliability of data because it ensures that there isn’t any data lost due to overloading um the receiving station Now TCP also contains something called a check sum mechanism and what this does is it assists with error detection the level of error detection isn’t as strong as that of some of the lower layers And you recall that this is in the transport layer of the TCP IP stack but it does catch some specific errors that may go unnoticed by other um layers And and by the way this check some basically it’s it’s sort of has a number that it creates based on the data and it can check that number at the beginning and at the end to make sure we haven’t lost anything Now this protocol attempts to alleviate MTU if you recall uh what we talked about with MTU there mismatches on the data link layer by establishing maximum segment sizes that can be accepted by TCP This is also going to reduce what we talked about earlier that MTU uh black hole Now further examining IP or the internet protocol which is aptly named and exists at the internet layer unlike TCP IP it’s characterized as being connectionless or a best effort delivery which is also like UDP which we’ll see in a second It outlines the structure then of information which is called datagramgrams or packets and how uh we’re going to package this stuff to send it over the network Now this protocol is more concerned with source to destination navigation or planning or routing as well as host identification and data delivery solely by using the IP address So this is slightly different from TCP which is doing stuff in a much more different way Now IP is used for communications between one or many IPbased networks and because of its design it makes it the principal protocol of the internet and it’s essential to connect to it So unless we are using IP address in today’s day and age we will not be able to connect to this big thing called the internet Now the terms connectionless and connectionoriented relate to the steps that are taken before the data is transmitted by a given protocol whatever that protocol might be with TCP we’re looking at connectionoriented and of course with IP we’re looking at connectionless and for instance the connectionoriented protocol is going to ensure a connection is established before the sending of data meaning it is oriented towards a connection whereas a connection less isn’t going to doesn’t matter if there is a connection established already So the next protocol which is also connectionless that we want to talk about is something called UDP Now since we have many applications and their functions depend on data being sent in a timely manner TCP and its connectionoriented properties hinder their performance In these cases we’re able to use something called UDP Again the user datagramgram protocol and UDP is connectionless just like IP is and it’s a that means it’s a best effort delivery protocol So with TCP if packets get delayed or if they’re needed to be resent due to a collision the TCP on the receiving end is going to wait for the lost or late packets to arrive Now with some sensitive data delivery this is going to cause a lot of problems And UDP is what we call a stateless protocol which prefers the packet loss over the delay in waiting So UDP is only going to add a check sum to the data for data integrity It’s also going to uh address port numbers for specific functions between the source and the destination nodes such as UDP port 53 for DNS which is one that you should remember from an earlier module Now UDP’s features make it a solid protocol and it’s used for applications such as VOIPE or voice over IP and online gaming This makes sense because we don’t care if every single little packet arrives What we want is we want the speed with which uh UDP is going to deliver stuff Obviously if we miss a couple packets in voice that’s okay they drop but we don’t want to have to wait until the next packet arrives That’s going to actually cause much more of a delay And so we’re going to use this one in more VOIPE and online gaming purposes Now the next protocol we want to be familiar with is called ARP and it’s also necessary for routing ARP or the address resolution protocol and the reverse address resolution protocol are request and reply protocols that are used to map one kind of address to another Specifically ARP is designed to map IP addresses the addresses that are necessary to TCP IP communication to MAC addresses which are also known as we’ve discussed in the past as physical addresses And again IP addresses work on the networking layer or in TCP IP the internet layer Whereas MAC addresses operate on the network interface layer of TCP IP which in OSI would be the data link layer layer two Now in TCP IP networking ARP operates at the lowest layer uh the network interface layer in total Whereas in the OSI model we say that it actually operates between uh the data link layer and the physical layer And this is because it wasn’t designed specifically for the OSI model It was designed for the TCP IP model Now ARP and RARP play very important roles in the way networks operate If a computer wants to communicate with any other computer within the local area network the MAC address is the identifier that’s used And if that device wishes to communicate outside of the local area network the destination MAC address is going to be that of the router So the ARP process works by first uh receiving the IP address from IP or the internet protocol Then ARP has the MAC address in its cached table So the router has what are called ARP tables that link IP addresses to MAC addresses We call this the ARP table So it looks in there to see if it know if it has a MAC address for the IP address listed It then sends it back to the IP if it uh if it does have it And if it doesn’t have it it broadcasts the message it’s sent in order to resolve what we call resolve the address to a MAC address And the target computer with the IP address responds to that broadcast message with what’s called a uniccast message And we’ve discussed that that contains the MAC address that it’s seeking ARP then will add the MAC address to its table So the next time we don’t have to go through this whole process and then it returns the IP address to the requesting device as it would have if it just had it Now RARP is used to do the opposite That is to map MAC addresses of a given system to their assigned IP addresses and it sort of works in reverse from all this Now that’s a very general overview of ARP and RARP and if you were to go into Cisco certifications for instance you go a little more in depth into this But for network plus this is really where we need to stop with this protocol So the next protocol I want to talk about is MP which is also called the internet control message protocol It’s a protocol designed to send messages that relate to the status of a system It’s not meant to actually send data So ICMP messages are used generally speaking for diagnostic and testing purposes Now they can also be used as a response to errors that occur in the normal operations of IP And if you recall one of the times that we talked about that was for instance with the MTU black hole when that MP message couldn’t get back to the original router Now many internet protocol utilities are actually derived from ICMP messages such as tracert or trace route path ping and ping and we will talk about these in a little more depth and if you were around for uh A+ we definitely talked about these two quite a bit ICMP is actually one of the core protocols of the IP suite and it operates at the internet layer which as you recall is TCPIP uh second layer Now ICMP is a control protocol used byworked computers and operating systems And the most common utility that we’re going to see is what’s called ping which we’ve talked about which uses what are called MP echo requests and they reply to determine connection statuses of a target system So I could ping a specific system to see if it’s on the network Of course there are some reasons why the ICMP as we’ve talked about might not make it back to me uh or it’s configured not to respond perhaps through a firewall Finally we need to talk about IGMP or the Internet Group Management Protocol It should not be confused with ICMP It’s slightly different It is used to establish memberships for multiccast groups Now multiccasting is where a computer wishes to send data to a lot of other computers through the internet by identifying which computers have subscribed or which ones wish to receive the data We looked at this earlier and determined that routers determine a multiccast group Now in a host implementation a host is going to make a request for an IGMP implemented router to join the membership of a multiccast group Now certain applications such as those for online gaming can use for what are called one to many communications the one being the game server and the many being all of those end users that have subscribed to the gaming session So those routers with IGMP implementation periodically will send out queries to determine the multiccast membership of those devices within range and then those hosts that have membership are going to respond to the queries with a membership report Now the process of delivering an IP packet is simple It begins with resolving the name of the host to its assigned IP address like we talked about with ARP and the connection is established by a service at if you recall the transport layer Now after the name resolution and connection establishment the IP address is then sent down to the internet layer and the next step is where the IP looks at the subnet mask which we’ve talked about in A+ and we’ll talk about more of the IP address to determine whether the destination is local to the computer on what we say is the same subnet or whether it’s remote or on another network After this determination is made then finally the packet is routed and delivered Okay so we now understand TCP IP a little more fully some of the protocols that are uh dealt with in great detail and uh how IP packet delivery works So let’s talk about binary and decimal which are going to be really important when we get into what’s called subnetting And it’s just good to know as an IT professional anyway specifically understanding binary or how to convert binary which is the number computers the way computers talk to decimal which is the way that we deal with numbers and decimal to binary pertains to a lot of different aspects of uh as I just mentioned networking So to begin with binary as the name implies from buy is what we call a base 2 system More commonly we used a base 10 system decimal Now this means that we have 10 possibilities for every place value We have between a zero and nine You add that up there are 10 Now with binary there’s only two options either zero or one So we can either have a single zero or a single one And that’s what we call a d a binary digit or a bit So the binary number has place markers that are similar to the base 10 system For instance if we have uh a a decimal base 10 numbering system the second place mark designates the 10 If we imagine that there’s a uh a period or a decimal right there the third designates the hundreds and then we move to thousands and 10,000 and 100 thousands and so on and so forth And in each one of these we can have anywhere from 0ero to 9 and that’s 10 options in each one of those spots Now in a base two numbering system which is binary we have only two options a one or a zero in either one of those places And in computers especially in uh a lot of IP addressing we really deal with the difference between uh eight different places So we’re going to call these eight an octet So this eighth place binary digit is referred to as an octet because there’s 1 2 3 4 5 6 7 eight of them And you’ll see these numbers pop up over and over again So this is really as far as you need to know for binary although you can go even further So if we look at this octet from the right side to the left the first place mark is what we call 2 to the 0 power Right If we were talking about this in 10 this would be the ones place Why Because it’s 10 to the 0ero power which is ones Anything taken to the zero power is 1 Next we have 10 to the first power which is going to equal two If you recall we call this the 10’s place 10 to the 1 power means 10 by itself is 10 Then we have 10 the second power which is 4 And if you recall in decimal this is 10 the 2 which would be 10 * 10 which is 100 You can see where this is going So 2 the 3r is 8 2 4th = 16 2 5th = 32 2 6 = 64 and 2 7 = 128 So each one of these place markers is equivalent to this number whether it’s turned on or off Now to help clarify this a bit each place here has one of two options correct Because it’s base two If it’s off that means it’s a zero as you see right here And the number means it’s not being counted So we don’t count any of these numbers we’ve just calculated So if all the bits are off that means that we have a number of zero If all of the bits are on then this means we add each of the numbers together So we get 128 + 64 + 32 + 16 + 8 + 4 + 2 + 1 which equals 255 Now believe it or not you can create any combination of numbers from just binary You don’t need decimal We’re going to see that in just a second So for example let’s say the binary number is uh 0 0 0 1 1 Well in this case the 128 64 32 16 and 8 bits are all off The only ones that are on are 4 2 and 1 And if we add those together 4 + 2 + 1 we’ll get 7 4 + 2 is 6 + 1 is 7 If we take another number say 0 1 1 0 0 1 1 0 then this is going to equate to 102 Why 64 + 32 = 96 + 4 = 100 + 2 = 102 So it’s pretty simple You just take the number with the ones under it and add them together So now that we’ve converted binary into decimal a number that we all know let’s go ahead and see if we can convert the other way decimal to binary Now for this process we’re going to use the same exact chart that we just saw with the binary conversion And this chart is going to help us visually represent all the binary digits which is why I like it And they’re placeholders and it makes it a lot easier So for decimal to binary we simply go from left to right and break down the number until we reach the zero So let me break that down a little bit For instance if we take the number 128 right This is pretty easy to convert We plug it into this chart How many times does 128 go into 128 One time If we take all the others and we subtract them we’re going to have zero right Because now 128 – 128 is 0 That leaves us with our binary number 1 0 0 0 which is equivalent to 128 Now if we take a look at a different number let’s say the number 218 this is going to take a little more math Does 218 go Does 128 go into 218 It certainly does So 218 minus 128 has a remainder of a certain amount which is 90 Does 64 go into 90 It does We now have a remainder of 26 Does 32 go into 26 No it doesn’t So we put a zero Does 16 go into 26 Yep it does Which leaves us with a remainder of 10 Does 8 go into 10 It does which leaves us a remainder of two Does four go into two It does not So that leaves us with zero We still have our two Does two go into two Yep And then do we have anything left over Nope We’re at zero now So we have zero If we now add all those up this is our binary number 1 1 0 1 1 0 1 1 0 Now while this might seem like a fairly long process it’s important to understand how this works because when we get into subnetting it’s really going to become important so we can have a better understanding of networking in general So just to recap everything we’ve talked about we described these protocols in the TCP IP suite First TCP transmission control and IP internet protocol One is connection oriented and the other is connectionless meaning that it just is worried about delivery Remember IP is what is responsible for that IP addressing UDP is also connectionless similar in some ways to TCP but it’s not connectionoriented Then we had ARP and reverse ARP address resolution protocol which job is to map IP addresses to MAC addresses We talked about MP which is what we use when we’re dealing with the status of a system Internet control message protocol and then we talk about IGMP the internet group management protocol which is more dealing with multiccast groups We then talked very briefly about the IP packet delivery process which was pretty simple right It’s packaged it’s sent we determine where it needs to go Once it’s determined where it needs to go it’s sent there Finally we explained the binary conversion which is going to be really important for IP addressing including how to go from binary which is a base 2 system to decimal which is a base 10 system and back again common network ports and protocols All right now we start getting into what I think is the fun stuff uh in this Network Plus exam In some ways it’s also where a good bulk of the questions are going to come from By the end of this module you’re going to be able to say what each of these numbers represents in terms of a protocol Now if you took the A+ exam and I hope you did uh you probably recall some of these from there So this might be a bit of a recap for you but that’s okay It never hurts to go over this stuff again especially because it just always pops up on the exam And as far as knowing stuff uh this is one of those things that you just have to know These these protocols are what you really have to know And we’re going to talk about the protocols in more depth later too when we talk about what TCPIP is But I want to start talking about these now since a port is really the end point logically of a connection So we’re going to start by talking about what a port is in a little more detail and outline the different port ranges There are three of them Well-known ports uh registered ports and then the last range which is um uh experimental sort of ports and private ports So we’re going to outline the most common well-known default ports and the protocols that go along with them I’m actually going to give you a huge list of all the protocols you need to know And we’re going to talk about some of those in depth in this module some in the next module and then some later on in the course But I’m going to get them all out onto a a chart for you right now Finally I want to define and describe the common ports and protocols dealing with FTP or the file transfer protocol NTP or the network time protocol SMTP simple mail transfer protocol POP 3 or the post office protocol the used to receive email as opposed to SMTP which is used to send email IMAP which is also used for um receiving or accessing email which stands for the internet message access protocol NNTP or the network news transfer protocol uh something you may have used if you’ve ever used RSS feeds HTTP or the hypertext transfer protocol and HTTPS which is the secure version These are what allow you to browse on the internet And finally we’ll talk about RDP or the remote desktop protocol which allows you to remote in to a Microsoft computer All right so let’s talk about these in more depth First off we have to define a port In computers and networking a port is a process specific or applications specific designation that serves as a communication end point in the computer’s operating system meaning where the communication logically ends once it reaches the user The port identifies specific processes and applications and denotes the path that they take through the network Now the internet assigned numbers authority or the AA is the governing entity that regulates all of these port assignments and also defines the numbers or the numbering convention that they’re given Now these ports range from one to over 65,000 Port zero is reserved and it’s never used So uh don’t really worry about that Now within this range we actually have three different subsets of ranges and as administrators knowing the common ports is crucial to managing a successful network The common ports are some of the guaranteed few questions that I I know you’re going to have on the network plus examination and nearly every other network examination as well So covering these and committing these to memory is of the utmost importance Now within that range from one to over 65,000 there are three recognized blocks or subsets of ports The first block is considered the well-known ports These ports range from 1 to 10,023 This is where we’re mostly going to look at ports uh when we look at them in just a minute These are used by common services and are pretty much known by just about everyone in the field Now the next range of ports is called the registered ports range These span from 1,024 to 49,151 These are reserved by applications and programs that register with the AA Uh an example might be for instance Skype which registers and utilizes port I think 23399 as its default protocol Uh don’t worry about that But if you’re curious for your firewall sake this is the port I believe Skype uses Finally we have the dynamic or the private port range This is everything else 49,152 to 65,535 These are used by unregistered services in uh test settings and also for temporary connections You can’t register these with the INA they’re just left open for anyone to use for whatever purposes you may need them So now let’s talk about the well-known default ports you need to know for the exam This chart is really what you should commit to memory since uh and when you get to the test you want to be able to basically recreate this chart before you sit down and take the test You’ll be able to do this on what’s called a brain dump sheet So let’s talk about the first portion of these ports we need to know The first is port 7 This is for the MP echo request or ping If you’ve ever pinged something from the command line this is what we’re talking about We’ll talk more about this a little bit later Next we have port 20 and 21 These are for the FTP or file transfer protocol which allows you to transfer files over a network We’ll talk more about this in just a minute Port 22 is for the secure shell or SSH and port 23 is for Telnet Both of those we’re going to discuss later on in a different module but they’re sort of allowing you to remote in and control a remote computer albeit not from a graphical standpoint Port 25 is the SMTP or simple mail transfer protocol which allows you to receive email and DNS or the domain name service which uses port 53 is what allows you to transmit uh or to translate say google.com into its IP address when you’re browsing out on the internet This is a really important protocol and we’ll talk more about it later along with the the DNS sort of server Port 67 and 68 are for what are called DHCP and bootp or the bootstrap service for servers and client respectively One for uh servers and one for clients As we can see right here we’re going to define and describe those in more detail in the next lesson Now port 69 is the trivial file transfer protocol This is related to the file transfer protocol we mentioned up here but it is trivial meaning that it is not uh connectionoriented and doesn’t really guarantee that the file has been transferred Port 123 is the network time protocol which keeps the clock on a network or on computers on the network up to sync A great way to remember this is that time is always counting 1 2 3 Uh port 110 is for the POP 3 or the post office protocol which is how many of us download our email onto our local device And then port 137 is the net bios naming service This is similar to DNS but is specific to Windows operating systems or Microsoft operating systems Related to POP 3 is port 143 which is IMAP the internet message access protocol This is another way of accessing and managing your email Let’s continue taking a look at a few more protocols that are equally important The first is the simple network management protocol which allows you to manage devices on network say by getting error messages from your printer or from a router This uses port 161 We’ll discuss this a lot more in detail later as well Port 389 is the lightweight directory access protocol This is what allows a Windows server to have usernames and passwords Port 443 is HTTPS or the hypertext transfer protocol over secure socket layer Notice the S here This is what is allows us to browse the internet but securely We also have port 500 which is IPSAC This one also has another name which stands for Internet Security Association and Key Management Protocol Basically IPSec or IP security is what allows us to have secure connections over IP Finally we’re going into RDP or the remote desktop protocol which allows us to remotely access a uh a computer Windows-based specifically port 119 or the network news transfer protocol which is not only used with Usenet a sort of message board that’s been around for a very long time but also RSS feeds which you might be more familiar with And finally port 80 is HTTP or hypertext transfer protocol The other thing to know about HTTP is it has an alternate port of 8080 So you might see either one of these on there All right Now I know that was a lot of information I just threw out there but we’re going to cover these all in a little more depth as we go through here and I just wanted to lay them out in a very simple chart-based way so that you could commit them to memory Now let’s talk about these in a little more depth understand how they function and why First up is the file transfer protocol or FTP This protocol enables the transfer of files between a user’s computer and a remote host Using the file transfer protocol or FTP you can view change search for upload or download files Now where while this sounds really great as a way to access files remotely it has a few considerations that need to be kept in mind The first is that FTP by itself is very unsecure and an FTP Damon which is a Unix term for a service has to be running on the remote computer in order for this to work You might also have to have an FTP utility or client on the client computer in order for you to have this protocol operate effectively and for you to be able to use it Now trivial FTP is the simple version of FTP and does not support error correction and doesn’t guarantee that a file is actually getting where it needs to It’s typically not really used in many actual file transfer settings Now just as I just mentioned you might need a client FTP uh software on your computer Generally speaking there is a command line prompt that you can use It goes like this FTP space the fully qualified domain name for instance google.com/FTTP which I don’t think is the actual one or the IP address of the remote host You only need one or the other If you provide the IP address you’re sort of using the direct route If you’re using what’s called the fully qualified domain name which we’ll talk about a little bit later then you allow something called DNS or the domain name service to do the translation into uh a IP address for you Remember again that FTP uses ports 20 and 21 by default Next is the simple mail transfer protocol or SMTP This is used to manage the formatting and sending of email messages Specifically we’re looking here at outgoing email Using a method called store and forward SMTP can hold on to a message until the recipient comes online This is why it’s used over unreliable wide area network links Once the device comes online it hands the message off to the server The SMTP message has several things including a header that contains source information as to where it’s coming from And it also has destination information as to where it’s going Of course there’s also content information which is inside of the packet The default port for SMTP is port 25 although sometimes you might see it use port 587 which is uh by relay I wouldn’t worry too much about that one for the exam but just keep in mind port 25 Now like SMTP POP 3 is a protocol that’s used in handling email messages and POP 3 stands for the post office protocol version 3 which is the commonly used version Now specifically POP 3 is used for the receipt of email or incoming email And it does this by retrieving email messages from a mail server It’s designed to pull the messages down and then once it does that the server deletes the message on uh the server source by default although you can change that if an administrator wants to This makes POP 3 not as desirable and weaker than most some other mail protocols specifically IMAP which we’re going to see because it puts all of the brunt of the responsibility onto the client for storing and managing emails and deletes all the emails at the source So if something happens to your computer and you don’t have a backup you’re in big trouble The default port for POP 3 as we mentioned is port 110 So remember port 110 is POP 3 and port 25 is SMTP Now IMAP 4 uh usually just called IMAP is the internet message access protocol and it’s similar to POP 3 in that it’s also utilized for incoming mail or mail retrieval But in nearly every way IMAP surpasses POP 3 It’s a much more powerful protocol because it offers more benefits like easier mailbox management uh more granular search capabilities and so on With IMAP users can search through messages by keywords and choose which messages they want to download They can also leave IMAP messages on the server and still work with them as though they’re on the local computer So it seems that the two are synced together perfectly the server and the client Also an email message with say a multimedia file can be partially downloaded to save bandwidth Now the main benefit here is we’re going to use this instead of for say a computer let’s say I have a smartphone and a computer Now it’s going to make sure because the source is all stored at the server that if I delete something say on my computer that syncs up to the server and then the server will have that sync with the my smartphone So all of these are in perfect synchronization This is why it’s much stronger than POP 3 which simply downloads the email onto your client device By default IMAP uses port 143 which is different from IMAP POP 3 rather which uses 110 Now NTP or the network time protocol is an internet protocol that synchronizes system clocks by exchanging time signals between a client and a master clock server The computers are constantly running this in the background and this protocol will send requests to the server to obtain accurate time updates up to the millisecond This time is checked against the US Naval Observatory master clock or atomic clock So the timestamps on the received updates are verified with this master clock server which is again that US naval server And the computers then update their time accordingly The port this uses is port 1 2 3 which is as easy to remember as time keeps moving up 1 2 3 Now if we add an additional n to the previous one we get what’s called the network news transfer protocol This is very different from the network time protocol It’s used for the retrieval and posting of news group messages or bulletin messages to the Usenet which is a worldwide bulletin board that’s been around since the 1980s really since the internet was in its nent stages The network news transfer protocol is also the protocol that RSS feeds are based on This stands for really simple syndication Basically this is where a user can subscribe to an article web page blog or something similar that uses this protocol and when an update is made to that page or to that article the subscriber is updated So in this way you can get updated articles from your favorite web page just like you would new emails With N&TP however only postings and articles that are new or updated are submitted and retrieved from the server Slightly different from RSS but RSS is based on N&TP The default port for this is port 9 So we’re covering a lot of different numbers here It’s really important perhaps even more than memorizing uh specifically what each protocol does that you definitely memorize which port it’s a part of If you can memorize by the way the number and what the acronym means you should be fine Now a protocol you use every day even if you don’t realize it is HTTP or the hypertext transfer protocol This is used to view unsecure web pages and allows users to connect to and communicate with web servers Although HTTP is going to define the transmission and the format of messages and the actions taken by web servers when users interact with it HTTP is what we call a stateless protocol meaning that it may be difficult to get a lot of intelligent interactive responses to the information If you remember ever making very basic web pages using HTML or the hypertext markup language the language that HTTP is reading then you probably know this So if you want more interactive web pages or interaction with web pages then you’re going to use different add-ons such as ActiveX that you might have heard of HTTP defaults port is port 80 And a common alternate port for it is port 8080 Now similar to HTTP is HTTPS or hypertext transfer protocol over SSL which is the secure socket layer This is a secure version of HTTP So if you ever see an S on the end of just about any protocol you can bet that that has to do with this being secure And it creates secure connections between your browser and the web server It does this using SSL or the secure sockets layer We’re going to discuss the secure sockets layer when we discuss encryption more detail in a future lesson Now most web pages support HTTPS and it’s recommended that you use it over HTTP almost every time you’re able to The way you do this is simply uh by using instead of httpfas.com just put an s in front Yes Facebook supports this as do other social media sites and even email and even Google supports https Why would you want to do this Well say someone is browsing and or listening in to your Google searches That might be information you don’t want someone else to know Just as a recommendation absolutely anytime you visit any website but especially financial uh institutions such as your bank or your credit union you want to ensure that in the bar it says https If it’s not then opening anything in this including typing in your bank password could be really serious The same goes for anything when we’re dealing with credit cards for instance buying something Make sure that HTTPS appears in the bar or in your URL bar at the top As we’ve mentioned before too the default port is port 443 Now the last port I want to discuss is RDP or the remote desktop protocol RDP servers are built into the Microsoft operating system such as Windows by default and it provides users with a graphical user interface or a guey to another computer over a network connection So this protocol allows users to remotely manage administer and access network resources from another physical location over the internet which is represented by the cloud There are a few security concerns that come with um RDP and there is potential for certain sort of computer attacks So there are also non-Microsoft variations available such as something called R desktop for Unix uh which if you are going to be doing a lot of remoting you might want to look into RDP by the
way uses default port 3389 although you can change that usually as well when we’re using RDP we’re also going to use it over what’s called a VPN or virtual private network which creates a tunnel through which your connection occurs This improves the security we were just talking about So let’s review what we’ve just talked about First we talked about a port being the logical endpoint of a connection and then we outlined the port ranges Remember we had the well-known ports the registered ports and then the dynamic or private or experimental ports What we really want to uh learn for ourselves are the well-known ports I then outlined the most common well-known default ports and their protocols You want to memorize this table for the network plus exam I guarantee you doing that will get you a bunch of questions on the exam Finally we defined and described some of the specific ports and not only and we looked not only at the proto and their protocols including FTP or the file transfer protocol NTP or the network time protocol SMTP or the simple mail transfer protocol POP 3 or the post office protocol We also looked at IMAP the internet message access protocol and again all three of these have to do with email We also looked at NNTP which is not network time protocol but the network news transfer protocol We looked at two different versions of HTTP One that is secure These allow for browsing and it stands for the hypertext transfer protocol which if you know HTML or the hypertext markup language then that might be familiar to you And finally we looked at RDP or the remote desktop protocol I know this seems like a lot but I guarantee memorizing all of these and all of the numbers that they’re associated with is going to help you so much on the exam Interoperability services This word interoperability is a really long one but it’s also a good one Basically what this means is how different types of operating systems and computers can communicate with one another over a similar network And that’s what we’re going to be discussing in this module So we’re going to first cover what interoperability services are in a little more depth Then we’re going to define some specific services that qualify as these particularly NFS or the network file system I’m sure you can imagine what that is from its name We’re also going to look at SSH which is the secure shell and SCP secure copy protocol Remember every time we see that S we want to think uh secure security That’s a great tip that’ll help you out on the test By the way secure copy protocol similar to SFTP or the secure file transfer protocol We’re then going to look at Telnet or the telecommunications network and SMB or the server messenger block which is what allows us to share for instance files and printers We’re also going to look at LDAP or lightweight directory access protocol And that word directory is important as it allows us to manage users in our network And then zero conf in networking which also stands for zero configuration networking a set of protocols that allows us to sort of plug in and go without having to do a lot of advanced configuration and setup This is what allows us to have very easy plugandplay network devices such as our SOHO routers which is a good way to think about it However it’s also deployed in much larger operations in order to ease the burden on administrators and technicians So in the previous module we discussed several different protocols that were used in the TCPIP protocol suite and uh these allowed us to do a lot of different things By the way TCPIP which is what basically allows us to communicate over the network in general is going to be discussed in more detail in depth later on in this course Now because not all computers are made the same or by the same people or individuals certain protocols and services need to be in place to allow dissimilar systems such as PCs and Macs to be able to interact with one another So TCP IP also contains these interoperability services that allow dissimilar services or systems to share resources and communicate efficiently and securely which is important if I want to make sure that no one is reading all of the information I’m sending between computers So these services is what we’re going to spend the rest of this module discussing Now the first service is the network file system It’s an application that allows users to remotely access resources and files Uh a resource being for instance a printer and a file being like a word document as though they were located on a local machine even though they’re someplace else This service is used for systems that are typically not the same such as Unix which is the uh larger version or the commercial version of Linux and Microsoft systems Now NFS functions independently of the operating system the computer system it’s installed on and the network architecture This means that NFS is going to perform its functions regardless of where it’s installed And since it’s what we call an open standard it allows anyone to implement it It also listens on port 2049 by default but I wouldn’t worry about memorizing that for the test Next SSH or the secure shell is one of the preferred session initiating programs that allows us to connect to a remote computer It creates a secure connection by using strong authentication mechanisms and it lets users log on to remote computers with different systems independent of the type of system you’re currently on With SSH the secure shell the entire connection is encrypted including the password and the login session It’s all compatible with a lot of different systems including Linux Macs and PCs and so on Now there are actually two different versions of Secure Shell SSH1 and SSH2 These two versions are not compatible with one another which is important to know because they each encrypt different parts of the data packet and they employ different types of encryption methods which we’ll talk about later However the most important thing to know is that SSH2 is more secure than SSH1 and so in most cases we want to use that This is because it does not use server keys SSH1 doesn’t which are keys uh that are temporary and protect uh other aspects of the encryption process It’s a bit complex and over the course of and over the uh objectives of this course However SSH2 does contain another protocol called SFTTP And SFTP or the secure file transfer protocol is a secure replacement for the unsecure version of plain old FTP and it still uses the same port as SSH which if you recall is port 22 So it’s important to know that if we’re going to be using SFTTP remember FTP uses 20 and 21 If we’re using SFTP we’re using port 22 Now similar to SFTP is SCP or the secure copy protocol which is a secure method of copying files between remote devices just like FTP or SFTP It utilizes the same port as SSH just like SFTP and it’s compatible with a lot of different operating systems To implement SCP you can initiate it via a command line utility that uses either SCP or SFTP to perform some secure copying The important thing here to know for the network plus exam is not when you would use SCP over SFTP which is a little bit more complex but rather to realize that SCP is a secure method of copying as is SFTP That’s how you’re going to see this pop up on the exam Now in contrast to all of this secure communications I want to talk about Telnet or the telecommunications network which is a terminal emulations protocol What this means is that it’s only simulating a session on the machine it is being initiated on When you connect to a machine via a terminal by using Telnet the machine is translating your keystrokes into instructions that the remote device understands and it displays those instructions uh and the responses back to you in a graphical or command line manner Tnet is an unsecure protocol which is why we don’t use it as much as SSH anymore And this is important to keep in mind So when you send the password over Telnet it’s actually in what we call plain text Whereas as we mentioned with SSH it transmits the password encrypted So if someone is reading the packets that are going back and forth they won’t be able to hack your system if you’re using SSH Whereas with TNET they’d be able to read your password Now Telnet uses port 23 by default which is important to know However you could configure it to use another port as long as the remote machine is also configured to use that same port With TNET you can actually connect to any host that’s running the Tnet service or Damon which again the word Damon is a Unix version of service SMB or the server message block which by the way is also known as CIFS or the common internet file system is a protocol that’s mainly used to provide shared access to files peripheral devices like printers most of the time and also access to serial ports and other communication between nodes on a network Windows systems used SMB primarily before the introduction of something called uh active directories which we’ll talk more about a little bit later This is currently what’s used in Microsoft networks Now Windows services that correspond are called server services for the server component and workstation services for the client component Now for example the primary functionality that SMB is typically most known for is when client computers want to access files systems or printers on a shared network or server This is when SMB is most often used Samba which you may have seen if you’ve ever dealt with a Mac or a Linux computer is free software that’s a reimplementation of the SMB or CIFS networking protocol for other systems Even though SMB is primarily used or was primarily used with Microsoft systems there are still other products that use SMB for file sharing in different operating systems which is why it’s important that we still familiarize ourselves with it LDAP stands for the lightweight directory access protocol And this is what defines how a user can access files resources or share directory data and perform operations on a server in a TCP IP network Now this is not how they access it This simply defines how a user can access it Meaning that what we’re really talking about here are users and permissions So basically LDAP is the protocol that controls how users manage directory information such as data about users devices permissions uh searching and other tasks in most networks We’re going to deal with this a little more in depth later on as well Now it was designed to be used on the internet and it relies heavily on DNS the domain name service which we talked about is a way of converting say google.com into its IP address We’re going to discuss DNS in greater detail in another module Now Microsoft’s Active Directory service which we just mentioned and Novel’s NDS and e directory services novel being another networking operating system as well as Apple’s open directory uh directory system all use LDAP Now the reason it’s called lightweight is because it was not as network intensive as its predecessor which was simply the directory access protocol No need to know that but I just wanted to explain the reasoning behind that lightweight in there Also it’s important to know that port 389 is used by default for all the communication of the requests for information and objects Finally zero conf or zero configuration networking is a set of standards that was established to allow users the ability to have network connectivity out of the box or plugandplay or without the need for any sort of technical change or configuration Zerocon capable protocols will generally use MAC addresses or the physical addresses as they are unique to each device with a nick or network interface card In order for devices to fit into a zero standard they have to fit or meet four qualifications or functions First the network address assignment must be automatic If you recall from A+ and this is something we’ll talk about a little bit later This is what we use when we’re using DHCP Second automatic multiccast address assignment must be implemented which is also related to the DHCP standard Third automatic translation between network names and addresses must exist This is what we talk about when we deal with DNS Finally discovery of network services or the location by the protocol and the name is required meaning that it must be able to find all of this information when it goes on the network automatically This is what allows users to be able to purchase a router from the local uh Best Buy or electronic store take it home plug it into their ISB or internet service provider connection and automatically have it work automatically Another implementation by the way of this is a configuration in networking called UPN or universal plug and play So to recap what we’ve talked about we talked about interoperability services which allows for instance a PC and a Mac to communicate flawlessly over a network We then talked about the network file service SSH and S SCP SSH being a secure shell working on port 22 and SCP being the secure copy protocol similar to SFTTP the secure file transfer protocol We looked at Telnet which is sort of a plain text version of SSH so it’s been replaced by it And SMB or the server message block allowing us to uh share files and resources between different types of systems Finally we described and defined LDAP or the lightweight directory access protocol which defines users and their ability to access all this stuff on the network And then we explained zero or zero configuration in networking which allows us to plug up a device and have it work almost instantaneously IP addresses and subnetting So having discussed IP addressing and routing in general we’re now going to further examine IP addressing and the methods of logically not physically dividing up our networks This way we can keep not only better track of all the devices on the network but also organizing them for security performance and other reasons After we complete this module we’re going to have a better understanding of how our network devices are identified both by other devices and by individuals such as ourselves since we’re not computers So first we’re going to identify what a network address is versus a network name One the network address is for other devices A network name is really for us since it would be difficult for us to remember all these numbers much like using a phone number in a cell phone Next we’re going to describe the IPv4 addressing scheme And uh IPv4 is important to know because even though we have a newer version IPv6 IPv4 is still uh deployed in most situations and it’s covered to the most extent on network plus when we get to IPv6 which is different version six uh there are a lot of benefits then and we’ll describe it later but really understanding IPv4 is really important after we take a look at that we’re going to look at subnetting and a subnet mask you might have seen this and uh these are the numbers and we’ve probably mentioned them in the past such as 255.255.0.0 zero and so on and so forth And we’re going to describe how this allows us to separate out the network ID from the node ID or the device’s ID or address from the network’s address much like our zip code versus our street address After that we’re going to describe the rules of subnet masks and their IP addresses And knowing binary is really going to help us understand all of this stuff After that we’re going to uh apply a subnet mask to an IP address using something called anding which again gets back to binary and might even remind you of something you learned in high school Uh this anding principle which is really going to come in handy And again this is something that we only have to do now with IPv4 IPv6 doesn’t have to do it and we’ll describe why Finally we’re going to take a look at what are called custom subnet masks which are slightly different from these default ones the 255 to 255 to 255s and so on So having said all that let’s get into it by looking at network addresses and names So let’s begin by looking at how nodes on a network are identified specifically on the internet or network layer If you recall the network layer is layer three of the OSI model and the internet layer is layer two of the TCP IP model So to begin a network address is assigned to every device and I think we’ve discussed this that wants to communicate on a computer network The network address is actually made up of two parts the node portion that belongs to the specific device and the network portion which identifies what network the device belongs to I think I’ve just described this as a zip code which describes the sort of network or the area you’re in versus your street number and your street address which is specific to where you live This address is what is used by devices for identification and as it’s only made up of numbers whereas a network name is made up of um letters and such The real reason being readability We would have a lot of trouble remembering We already have trouble remembering a phone number Uh but if you imagine remembering a whole binary number or set of numbers where there’s infinite possibilities unless you’re using it a lot it’s easier to remember a name such as the conference room laptop or resource server 1 than it is to remember an IP address which might be something like 132.168.56.43 Especially when there are a lot more computers involved the names become a lot easier So the network named is actually mapped to uh the address or the IP address by one or another naming services and some of these we’ve discussed Now as devices only communicate with each other by their network address the naming services are really crucial to the operation of a network There are three different network services used that you should be aware of The first DNS which we’ve mentioned before also called the domain name service is a naming service that’s used on the internet in most networks It’s what allows for instance you to type in google.com which we would call a fully qualified domain name and it will translate that to the IP address of Google whatever that might be The next naming service is Windows specific and it’s called WS or the Windows Internet Naming Service It’s really outdated and it was used on Windows networks Uh the only reason I mention it is you might see it mentioned in a test question and it might help you but you’re really not going to see it used in the field much anymore And finally we have one called Net BIOS which is a broadcast type of service that has a maximum length of uh 15 characters and uh it was used or still is used to a certain extent on Windows networks as well A good understanding of all of these network identification aspects addresses and names uh is important at this very fundamental level So now that we sort of have a general overview of these let’s take a look at some of the specific type of network addressing specifically IP version 4 Now IPv4 IP version 4 addresses is a very important aspect of networking for any administrator or uh technician or even just uh you know IT guy to understand It is a 32bit binary address that’s used to identify and differentiate nodes on a network In other words it is your address on the network or your social security number with the IPv4 addressing scheme being a 32bit address And you can see if we counted each one of these up remember a bit is either zero or one And we can count up there are 32 of these This means that there are theoretically up to 4.29 billion addresses available Now that might not sound uh like we’re ever going to hit that but in fact we’ve already gotten there And so part of the problem is how do we share 4.29 billion devices with 4.29 billion addresses with even more billions devices in the world So this 32bit address which is why we’ve had to develop another one called IPv6 But anyway I digress The 32-bit address is broken up into four octets This makes it easier for people to remember and to read And you can see those here And if you’ve ever seen like a 192.168.0.1 those are the four octets This system and structure of these address schemes is governed and managed by two standard organizations One is called the AIA which stands for the internet assigned numbers authority and the other is called the RIR or the regional internet registry I wouldn’t worry about memorizing these I’m just mentioning them so you know sort of who’s coming up with all this stuff Now every device on the network is going to have its own unique address So there are two types of addresses in general One is called class full and these are default addresses and the other are called classless which are custom addresses We’re going to talk about the classless ones in a later module And we’re going to define both of these in greater detail a little bit later on As a network address it’s also made up of two parts The network portion and the node portion Let me just erase all this writing here So you can see exactly what I mean in order to tell Now in this section you can see the network portion are the first two octets and the node portion are the last two octets But that is not always the case In fact if we were to just take those away for a second uh and this is how the computer looks at them we can’t actually tell which is which And that’s why we need something called a subnet mask The subnet mask allows us to determine which is the network portion and which is the node portion That way we know for instance where the area code of the phone number begins and the rest of the number ends So the network portion would be like the area code of your phone number or the international code It tells you which network that is on The node portion tells you exactly which phone on that network we’re going to try reaching out to So we’re going to further logically again not physically divide uh a network into smaller subn networks called subnetss Now this logical division is beneficial because of three reasons one it can effectively increase the efficiency in packet routing because if I know that uh my information is destined for a specific network I don’t have to bother with asking let’s say 5,000 or 5 million or 5 billion computers if I’m meant for them I can go directly to the network where I want to go just like with area codes and phone numbers The next is it allows for better management of multiple networks within a single organization Uh for instance if I’m a network administrator it might be easier to have separate subnetss so I can organize who’s on which subnet So that way not only are things going to be routed more efficiently for that person but it’s easier for me to manage on paper and uh in my administrative duties And finally it potentially offers a certain level of security since I’m only going to be able to access easily information that’s on the same network or subnet network that I’m on Now a subnetted IPv4 address is actually comprised of three different parts The net ID the host ID and the subnet ID Now if a device on a subneted TCP IP network wants to communicate it’s going to need to be configured with an IP address and a subnet mask And we’ll look at these in just a second The subnet mask is what is used to identify the subnet that each node belongs to This also allows us to determine which network it’s on Connectivity devices such as routers or upper layer switches And we’re talking about layer three devices here And remember layer 3 devices look at IP addresses not just MAC addresses are used on the borders of these networks to manage the data passage between and within the network That’s how we’re going to get better routing efficiency easier management and potentially make it more secure Because if I have any one network and I have a let’s say a switch we’ll put this a switch and it has four computers on it And then I have another switch and these are layer 2 switches Okay And each of these let’s say we have our different subnets Then I’m going to divide these up by a router which now is going to make sure that data that’s going here kind of gets bounced back unless it’s meant for this guy And this way we’re really reducing the traffic on it Now a subnet mask is like an IP address a 32bit binary address broken up into four octets in a dotted decimal format just like an IP address And it’s used to separate the network portion from the node portion I’m going to show you how that works in just a minute And it involves a little bit knowledge of binary which we’ve already talked about So the subnet mask and that name mask sort of lets you think of it as being put onto the IP address is applied to that IP address and removes the node ID The subnet mask therefore eliminates or removes an entire octed of the IP address by using eight binary ones or 255 in decimal format Meaning that this 255 if we add it up in binary would be 1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8 and then this would be 1 2 3 4 5 6 7 8 So meaning that a 255 equals 8 1’s which is the reason why an IP address can never be 255 And uh if this is a little confusing that’s okay We’re about to clarify that in just a second So IP addresses IP address assignments and subnet masks all have to follow a certain set of rules I’m going to describe the rules and then I’m going to apply them So if some of this is a little confusing or over your head keep paying attention Keep with me and I think it’s going to clarify itself The first is that the ones in a subnet mask will always start at the left Meaning the first octet will always be 255 or 8 binary ones So my I my subnet mask I’m always going to start at the left when I’m writing it out This says that the first octet is going to be 255 which means eight bits Now the zeros of the mask will always start at the one bit or all the way on the right meaning that I’m going to have zeros from the right and ones from the left And the ones in the mask have to be adjoining adjoining or conti consistent or continuous or contiguous whichever word you want to use Meaning once there is a zero we cannot then go back to ones So we’re not going to see like this sort of thing happen In fact we have to have continuous ones from the left and continuous zeros from the right This is the only way a subnet mask is going to work And I’ll talk about why in just a minute Also if there is more than one subnet on a network every subnet has to have a unique network ID And I’ll explain this in a bit but it makes sense If I have different network IDs then I’m not really uh I’m sorry if I have similar network IDs then I’m not really dealing with multiple networks I’m dealing with the same network Now assignment of IP addresses have to follow a few more rules So these are the subnet masks First there cannot be any duplicate IP addresses on the network This means that every network every device has to have its own unique IP address We cannot have more than one device with the same IP address If we do they’re not going to be able to communicate because the switches won’t know where to send packets Next if there are subnets every node must be assigned to one of them Meaning that every address every IP address has to be assigned to a specific network Now the address of a known cannot be all ones or all zeros Remember all ones would be 255 All zeros would be just 0.0.0.0 So I cannot have an IP address that is either 255.255.255 255 or that can be 0.0.0.0 And you’ll see why when we get to the mathematics of this in just a second It’s because then I would never be able to determine uh a network ID from a node ID Finally and this is something you sort of have to remember the IP address can never be 127.0.0.1 We talked about this in um A+ but that’s because this is what’s called the loop back It’s a reserved IP address specifically for yourself Be like saying me myself or I I cannot have uh a 127.0.0.1 IP address assigned to a device because every device calls itself 127.0.0.1 Now besides understanding these rules which are a bit abstract I think we need to know how to apply them and how to apply a subnet mask to an IP address I think it’s going to make some of these rules a little clear So let’s take a look at those Now when a subnet mask is applied to an IP address the remainder is the network portion Meaning when we take the IP address and we apply the subnet mask and I’ll show you how to do that in a second what we get as a remainder what’s left over is going to be the network ID This allows us to then determine what the node ID is This will make more sense in just a minute The way we do this is through something called ending Anding is a mathematics term It really has to do with logic The way it works is and you just have to sort of remember these rules One and one is one One and zero is zero And the trick there is that that zero is there 0 and 1 is zero And 0 and 0 is also zero So basically what ending does is allows us to hide certain um address certain bits from the rest of the network and therefore we’re allowed to get uh the IP address uh or rather the network address from the node address So let’s take a look at this for just a second Let’s say we have an IP address 162.85.120.27 27 and we have a subnet mask of 255.255.255.0 Now let’s take a look at how this works when we move it into binary 162.85.120.127 equals this in binary And if we wanted to um write out these places again if you remember we had this was a base 2 right So these are the place settings I’m just going to write these out real quickly and then I’m going to erase it all Okay And so we get 1 2 4 8 16 32 64 128 And it’s good to sort of commit these to memory Therefore the reason this is 1 one 1 is we take that 128 we add it to 32 and we add it to the two because those are the bits that are on And when we add 128 + 32 we get 160 + 2 gives us 162 So it works out And you can see my math is correct here I’m going to erase all this Now try to remember this and thing in here for a minute Now if we convert 255.255.255.0 into binary we’ve already talked about this We’re going to get all these ones And then because this is zero we’re going to get zero Now if we apply the anding principle this is what we’re going to get Anything with one and one turns into a one Anytime we see a one and a zero we’re going to get a zero And if we apply this out here’s what we get Now because we have all these zeros here it’s basically going to block all these ones from coming down and coming through right They all turn into zero So if we convert this back into a decimal we now get 162.85.120.0 Basically and this is pretty simple to see we can see that the 162 drops down the 85 drops down the 120 drops down because of this ending that we just talked about and the 27 gets blocked by these zeros And so we can determine that the 162.85.120 is what we call the network ID Now by looking at it this way we can see then that the network portion of the address is going to be the first three octets as we just pointed out and the node portion is going to be the last octed So this is the first step in subnetting and it tells us a lot of things about the networks Just by knowing the IP address and the subnet mask a technician can now discern a lot of things such as what portion is the network ID what portion is the node ID and therefore what is my first usable IP address and what’s my last usable IP address that I could start to give to devices I can also determine stuff like what we call the default gateway which we’ll look at in a second and the broadcast address which we’ll also look look at not in a second than in the next module Now there are three default subnet masks as you can imagine and these have to do with what we call a class uh a classful IP addressing system and we’ll talk about that next the next module but the default subnet masks are 255.0.0.0 just going to go with the class A and we’ll talk about that 255.255.0.0 and 255.255.255.0 What you can see is if you have a default subnet mask then you know immediately just by looking what the network address is and what the node address is As you can imagine if I have this as my network address I can have a lot of networks and only so many nodes This one I have more nodes a little bit less networks And in this one I have a lot of nodes but fewer networks to divide them up on Now it would be great if all subnet masks were as simple as this We wouldn’t even really ever have to break it down into this binary sort of coding because you could just look at it and say “Oh it’s 255 I know they’re all going to be ones I know that’s going to end out and therefore I know what’s going to end up right here.” But unfortunately this is not always the case Sometimes we have what are called custom subnet masks Now by using a custom subnet mask we can actually further divide or subdivide our IP address and in these cases it can be a little more difficult Uh and so converting to binary is actually necessary to break it down Custom subnet masks are created by what we call borrowing bits from the host portion to use to identify the subnet portion So you can see we’ve just borrowed a bit this one right over here Now keeping in mind that the subnet mask rules allow us to borrow bits from the node portion and give them to the network portion the bits from the left to the right of the portion like this are switched on Now turning this bit on means we now have different values for the subnet mask Instead of just 255 255.0 zero We know this is no longer zero right So this is actually now going to be 128 And we can have uh a number of these and if you keep adding over to the right so 128 and then we added 64 we get 192 and so on and so forth So we can actually have a number of custom subnet mask values in the last octed and that’s those are these And so you can see in this case uh it’s not really going to make much of a difference when I all do all the binary bidding uh because you see that the zero and the zero is still going to become a zero here And so all of this is really going to look the same And so our network portion is actually going to look the same uh as it did before We have the same network ID as we did before But let’s say that this was actually uh you know this number by the way is the same as the one we had before 162.85 85.120.27 If this was instead 162.85.120 dot I don’t know 2 12 28 We’re going to have an issue because this is going to be on These would say let’s be off And when they come down this is going to turn into a zero as opposed to that one dropping down And so it’s going to change what our IP address in the end looks like And so we actually need to do some backward engineering to get to our subnet mask Now this is all really complex and when we get into if you ever get into Cisco you’d really have to know this But for our purposes you really don’t need to know this stat in depth All right So just to recap what we talked about here we got a basic understanding of a lot of things Not too in-d depth And you might need to rewatch this video to really get it and maybe even do a little bit of exercises on your own First we talked about the difference between a network address and a network name Remembering that the three network name services that match a name such as Bill’s laptop to an address which would be something like 192.168.0.1 uh we can use either DNS the domain name service which is the most popular one something called winds which is specific to Windows or Net BIOS also a Windows-based naming system The one we want to be most familiar with is this This one’s not really used anymore Net BIOS is still used in certain instances especially in older networks We then talked about the IP version 4 address and the things that it requires including and remember a IPv4 address is that 32bit broken up into four octets The reason it’s called an octet is because we have 8 uh * 4 gives us that 32 and we break it up So for instance 192 is going to break down to a certain uh amount of bits Okay we also talked about defining subnetting and a subnet mask which the most important thing it does is distinguishes our network from our node ID In other words what’s our area code and then what is our phone number We can have the same phone number in different area codes but they go to very different people We also talked about the rules of subnet masks and IP addresses We can only have one IP address on any network and we can not use 127.0.0.1 because that is what we call the loop back address As far as for the subnet mask remember that all ones have to be continuous from the left and zeros have to be continuous from the right Our defaults are 255.255.0.0.0 and then 255 I’m sorry I think I just said 255.0.0.0 255.255.0.0.0 and 255.255.255.0 Those are our defaults And so we talked about applying a subnet mask using something called anding and we looked at how that divides up again the network ID from the node ID and we saw that in practice Finally we talked very briefly about custom subnet masks something that we don’t have to get very much into but we talked about how if we had 255.25.25 255 dot for instance 128 we could have these sort of sub subnetss or these uh we could break it down even further and therefore we could start to do a lot more stuff and in the next module I’m going to talk about this in a lot more detail and why we would want to do it default and custom addressing so we described in the previous module subnetting how to determine the network from the node ID and we talked specifically about IPv4 and we’re going to continue talking about IPv4 a little bit more first by defining the default IPv4 addressing scheme Now some of this we sort of touched on in the previous module and some of the stuff we’re going to talk about right now is going to probably help clarify that and so might I it might even help to go back and watch the previous module after watching this one After that we’re going to talk about the reserved or restricted IPv4 uh addresses One of the ones we’ve already mentioned is what we called the loop back or 127.0.0.1 That’s an example of a reserved IP address or restricted IP address And so we’re going to talk about those in more depth and some of the ones that uh some of the ranges that are restricted and why they are Then we’re going to discuss uh what are called the private addresses and we’re going to talk about these specifically because these are different from public IP addresses Uh one you might be familiar with is the 1 192.168 uh public private addresses rather And you this is going to explain why every router that you purchase at you know electronic store has this as its default Not everyone but a lot of them have this as the default IP address And yet we talked about how you can’t have more than one IP address with any device And so we’re going to describe why with private IP addresses this is the case And we’ll talk about some other private IP addresses as well Then we’re going to talk about the IPv4 formulas And that’s the that’s what allows us to determine how many hosts and networks are permissible based on the type of IP address the class that it’s in and the subnet mask that’s applied And this will help us also determine and talk about in a second uh why we might want to use custom subnet masks and custom IP addresses So then we’re going to talk about the default gateway is this gets back to actually this right here It is the uh device which um the any node needs to know in order to get out to the network and to the rest of the um the rest of the world Finally we’re going to talk about custom IP address schemes V LSM and CID Uh these are a little more in depth but these really get back to the subnet masks and why we can apply those uh how we can apply sort of specific subnet masks to things And we’ll look at this thing which you might have seen C which is has to do with why there might be a slash after an IP address which really gets to the number of bits it has and we’ll talk about that in just a minute Now aside from being an aspect that’s covered in many areas of the network plus exam understanding the classes in a default IP address scheme is really important for us And this gets back to uh right here So let’s talk about remember we talked about class less and class full We’re going to talk about the classes that exist in an IP address right now So as we learned in previous modules the IPv4 addressing scheme is again 32 bits broken up into four octets and each octet can range from 0 to 255 Now the international standards organization I can which we’ve mentioned in a previous module is in control of how these IP addresses are leased and distributed out to individuals and companies around the world Now because of the limited amount of IP addresses the default IPv4 addressing scheme is designed and outlined which what are called classes and there are five of them that we need to know Now these classes are identified as A B C D and E And each class is designed to facilitate in the distribution of IP addresses for certain types of purposes Now the first class a class A allows you to have uh is designed for really large networks Meaning that it does not have a lot of networks because we only have a few of them And that is because a class A range goes from one to 127 in the first octet Meaning that the remaining octets are reserved for nodes And so we see that we don’t have a lot of networks We only have 126 networks 1 to 127 But we do have up to 16.7 or8 around about million uh eyed nodes that can be on this network and so uh we have so many nodes for so few uh networks and so this is really for very large large networks and there are some specifically reserved addresses in this as well and we’ll talk about those in just a minute Now with class B here we have 128 to 191 and these are called class B They allow for a lot more networks and fewer nodes which makes sense Now the default subnet mask for a class A which might make this a little clearer 255.0.0.0 0 Whereas for a class B it’s 255.255.0.0 Now as you can tell the class is actually determined by the very first octet the number in the first octed And it’s important to then therefore memorize these numbers because you’ll see on your exam they’ll ask you which class is this IP address a part of If it’s between 1 and 127 you know it’s a class A If it’s between 128 and 191 you know it’s a class B If we get to a class C now we have a lot of networks and not a lot of nodes And you can see that these are 192 to 223 in the first um uh octet And the default subnet mask for this is going to be 255.255.255.0 And if you remember that gives us only this octet for nodes and all of these octets for networks This is usually one of the most recognizable for home networks because we have the 1 192.168.0.1 for instance that is going to obviously fall into this class C Now there are two other classes They’re not very common but they’re important to be able to recognize There are class D IP addresses which are only used for what we call multiccast uh transmissions and these are for special routers that are able to support the use of IP addresses within this range You don’t really need to worry about this for much application unless you’re dealing with uh a lot more advanced stuff And these deal with 224 to 239 Finally we have class E which is from 240 to 255 And these are really for uh experimental reasons So we’re really not going to see these in much play The ones you really want to be familiar with are these first three classes A B and C Remember 1 to 127 is a class A 128 to 191 is a class B 192 to 223 is a class C If you can remember those ranges I would commit them to memory You’ll be good to go for the exam Now within each of these classes uh there are a number of addresses that are not allowed to be assigned or leased for specific reasons These are what we call reserved and restricted IP addresses Now we’ve mentioned the 127.0.0.1 or the local loop back or the local host IP address before which can’t be assigned because it’s reserved for me for myself for for I This means that this address is used when I want to address myself So if I wanted to for instance assign myself my own name via DNS and my name was me me would link up to the IP address 127.0.01 And that way it’s going back to myself Now we’re really going to use this for mostly diagnostic purposes if I want to double check to make sure for instance that TCP IP is running correctly uh and it’s also going to be used for programmers and such like that Now the address 10.0.0.0 is also restricted and it’s not available to use because again this a host address can never have all zeros Conversely the addresses that have all ones for instance 255.255.255.255 255 cannot be used for um uh addresses Obviously this one can’t because it would sort of ruin the use of a subnet mask But even if I had something like 192.168.0.255 I can’t use that because that’s what’s called a broadcast address And so it’s just simply reserved for that This means that if a message is transmitted to a network address with all ones in the host portion or 255 that message is going to be transmitted to every single device on the subnet It’s called a broadcast And we’ve talked about broadcast before Finally the address 1.1.1.1 cannot be used uh because this is what’s called the all hosts or the who is address Um so these basically whereas 127 is for me 1.1.1.1 is for everyone So these we can never use The important one I really want you to remember here is this one And you’re going to want to remember that for instance 255 in the host portion can never be used again Not only because that’s going to ruin a subnet as we’ve talked about but also this is reserved for what’s called a broadcast address Now there are portions of each class that are allocated either for public or private use Private IP addresses are not routable This means that they are assigned for use on internal networks such as your home network or your office network When these addresses transmit data and it reaches a router the router is not going to uh route it outside of the network So these addresses can be used without needing to purchase or leasing an IP address from your ISP or internet service provider or governing entity So this is how I could create an internal network in my home and I don’t need to go register it Uh and I might not be able to access the internet but I don’t need to register it If I want to go out to the internet then I can share using devices and uh resources we’ve talked about previously and we’ll talk about later a public IP address with all of the internal devices that are configured using private IP addresses Now since these are not able to be used externally to our network these IP addresses can be used by as many devices as necessary as long as we never double over one IP address per device So the class A private IP address range remember we talked about 10.0.0.0 because we cannot have zeros right remember 10.0.0 and 255 we actually cannot assign but any address in between that so 10.126.5 would fall into what’s called a private address range and you might see this in your home router as well So this makes it easily discernible from other addresses in its class Anything that has the 10 to begin with cannot be used on a class A network or any network except privately We also have a class B uh private exchange which is 172.16.0.0 through 172.31.255.255 and class C which is 1 192.168.0.0 through the 255 to255 This one you might have seen the most This one I’m guessing you’ve seen the last This one’s probably the second most common the 10 dot So if you have a internal network at your home you might have your address on your computer right now For instance if it’s not connected directly to the network if it’s connected to a router might be something like this or like this or even like this All right that’s because these are each private addresses It’s important that you commit these to memory as well because these will appear on the exam And remember the important thing with a uh with a private IP address as I mentioned right here is they’re not routable and I don’t need a lease to use them So when tasked with subnetting a network you need to understand how to calculate how many hosts and how many networks are available If we want to determine the number of hosts that are available we apply this formula 2 to the x minus 2 And this is where x equals the number of node bits And that’s after we break it down from decimal to binary Now the reason for the minus2 here is because again we cannot use a0.0.0 address or a.255 255.255.255 address which would mean all zeros or all ones in the subnet And so we need to make sure uh rather in the um uh in the bit right when it’s broken down And so we need to make sure that um this is the case We also need to know the number of networks And to do that we’re going to do 2 to the y minus 2 where y equals the number of network bits So let’s take a look at this If we have the IP address 16285.1207 and we have a subnet mask of 255.255.255.0 By the way we can look at this and we automatically know that 162.85.120.27 27 This looks like a class B IP address And the 255 to 255 to 255 is actually our default class C subnet So this is not the default that we’re working with here So we need to figure out uh some information here So let’s break it down into bits And I’m going do that here And if you wanted to check my math you could Now the number of network bits is right here the Y And the number of node bits is right here the X So if we pop this into our equation the number of possible hosts we have is 254 and the number of possible networks is over 16 million If we go back to that table we saw a few slides ago we’d see then that that’s why we have a default for class B and class C networks is we can see how many networks are possible and how many hosts are possible Now why would I want to know this Well let’s say that I have to divide up my network and I want to have a certain number of networks and a certain number of hosts Well if I only need five networks but I need 30,000 hosts I’m going to be in major trouble here because now I have to divide this up so much I’m wasting a lot of networks and I don’t have enough hosts So we want to determine how we can do this to reduce the amount of waste And we’re going to talk about that in just a bit Going back to something called a default gateway for a second the for any device that wants to connect to the internet has to go through what’s called a default gateway This is not a physical device This is set uh by our IP address settings It is basically the IP address of the device which is usually the router or the border router that’s connected directly to the to the internet If for instance we had other routers in here um this is going to be the gateway And so three things need to be configured on any device that wants to connect to the internet We’ve talked about it We need to have an IP address a subnet mask and this is the new one a default gateway So this is the device that’s used when I want to communicate with the internet and it’s not used when communicating with devices on the same subnet This is why it’s called a gateway Think about it as your gateway out to the network Most often and more often than not as I mentioned this is going to be the router So if you have at home for instance a router that’s 192.168.0.1 0.1 that is also your default gateway and if you went in and did an IP config all something we’ll take a look at later and command prompt you’d be able to see then uh your default gateway is this address basically it means hey I don’t know I want to get out to the internet I don’t know how to get to Google I’m going to ask my default gateway the default gateway then takes care of everything else and then the information comes back and it sends it out to you again now there are a couple different ways of implementing custom IP addresses We previously described how we could use custom subnets and with that method a custom subnet mask and an IP address is what we call anded if you recall and uh together they allow the node to see the local network as part of its larger network Now each customized subnet is configured with its own default gateway allowing the subnets to be able to communicate with each other Now another method of doing this is called VLSM or variable length subnet mask And by using this we’re going to assign each subnet its own separate customized subnet mask that varies Now the VLSM method allows for a more efficient allocation of IP addresses with minimal address waste which I was just talking about So for example let’s take a situation in which a network administrator wants to have three networks and I have a class C space Now just so you know some of this is very outdated and we’re not going to see it used a lot of the time That being said Network Plus really wants you to know about it so we’re going to cover it So I know I need to have three different networks or sub networks And I know on the first network I want to have four hosts On the second network I want to have 11 hosts And on the third network I want to have 27 hosts Now in order to accomplish this I could use the subnet mask 255.255.255.20 that 224 And for each of these subnetss if I was to add this out right 1 2 3 4 5 6 7 8 That’s 285 1 2 3 4 5 6 7 8 That’s 285 1 2 3 4 5 6 7 8 That’s 285 Let’s write 224 in bits All right Um let’s go through our calculation again here I’m just going to do this because it never hurts to do this a couple times So let’s write all of these out Great All right we have 1 2 4 8 16 32 64 128 Now we remember that subnet masks have to have continuous ones So that’s 128 128 + 64 is 192 + 32 is 224 So then if we broke this down into bits this is what it’s going to look like Okay So let’s write that out here And if we do our calculation we know we need to have how many hosts Well we need four So let’s do our calculation 2 to the 1 2 3 4 5 power right We’re going to figure out how many hosts that equals we already know is 32 minus 2 means that we can have up to 30 hosts on this subnet So I’m wasting in effect 26 addresses on this subnet 19 on this one and three on this one I’m not really doing a good job because I’ve had to apply the same subnet mask to every single IP address And in doing so I’m wasting a lot of my possible addresses Now if I used VLSM instead I’m just going to erase all this I could do 255.255.248.240 and224 Now remember uh 248 if we wrote that out I’m just going to really quickly All right And you can double check my math here If we do 248 that is going to be 1 one one one 0 0 0 All right And then if we do our calculation 2 to the 3 because we have three host bits What does that equal 8 – 2 Well now we have a possibility of six hosts So what is our waste Two Because 6 – 4 = 2 A lot better right If we do the same thing with uh the next one and you were to do the same thing I just did that would look 1 1 1 0 0 0 We did the calculation again 2 to the 4 because now we have four bits – 2 which equals 16 – 2 which equals 14 So now I’m only wasting three bits because 16 sorry 14 – 11 equals 3 And finally 224 is the same Remember that was 30 bits or 30 hosts rather 30 – 27 is 3 So doing this variable we are a variable subnet mask we’re no longer wasting as many host addresses So by utilizing this we’re going to appropriately plan and implement a scheme and it allows us to use our space much more effectively Of course the negative aspect of this is it’s a lot more harder to scale And if I want to add nodes to these customized networks I might have to go around and change all the subnet masks as well Now cider which is cirr which stands for classless inter domain routing is also commonly called supernetting or classless routing It’s another of method of addressing that uses the VLSM but in a different way as a as a 32-bit word So the notation is much easier to read because it combines the IP address with this dash after it For instance the number is what denotes the amount of ones in the subnet mask from left to right So if we look at this notation right here we have 192.168.13.0/23 0/23 Well the 23 means there are 23 ones from left to right in the subnet mask Okay And now if we were to convert that this allows for a possible amount of host addresses 2 to the 9th minus 2 which equals 510 addresses So this allows for more than one classful network to be represented by a single set Basically we can now break it up further into smaller subn networks If we look at three of the most easily recognizable ones just going to erase this so we can get a better look here Uh the slash8 the slash16 and the slash24 We can see that these translate basically over to the basic class A class B and class C networks right Because slash8 class A that means it’s 1 1 or 1 2 3 4 5 6 78.0.0.0 which would mean 255.25 uh.0.0.0 which is our default subnet mask for class A Because again this is my network ID is the first octet and the node ID are the last ones and you can see that that would fall out for the next ones as well So because of the ease by which it is uh we can subnet networks this way because of readability and efficiency cider notation has become extremely popular and wider widely adopted Most of the internet in fact has become classless address space because of this meaning that we don’t really use classes and when we get to IPv6 we’re not going to see it at all Now again this is very complex The important thing I just want you to remember on this whole thing is that if you see this dash after an address here you know exactly what the subnet mask is and then you can backwards engineer or forward engineer the IP address uh or the network ID or node ID So just to review some of the points that we covered here we started by outlining the IPv4 addressing scheme We looked at the five classes The three I really want you to be aware of are A B and C Remember A is anything in the first octet That’s 1 through 127 With class B we’re looking at anything from 128 to 191 And with class C we’re looking at anything from 191 or rather 192 to 223 Anything else here we’re really looking at experimental and stuff that we don’t really need Remember these ranges for that first octed It’s easy then to determine what class we’re looking at Okay So we also described the reserved or restricted IP addresses For instance we can’t have anything with a0.0.0 zero or with a 255.255.255 because these are multiccast addresses And we also can’t have anything with 127.0.0.1 ever or 1.1.1.1 because these are both ones the local host one is the who is address We then looked at uh private IP addresses Remember we had three different ones each for each class For class A it was anything 10.x.x.x With class B it was 172.16.x.x through 172 31.x.x And the one you’re probably most familiar with is the class C which is 192.168.x.x Remember that Uh you can see what class they’re in by looking at this And most importantly class A private IP address going to allow for the most networks the fewest I’m sorry the most nodes the fewest networks Class C is going to be the complete opposite I’m going to allow for the most nodes the most networks rather but the fewest nodes Okay And again remember these ranges cuz they will come up What is make a private IP address It is not routed past a router onto the public network Okay we also talked about the IPv4 formulas which allow us to determine how many hosts or how many networks are allowed on a network and that is where the X or the Y equals the number of host or network bits We defined the default gateway which is what I need to get out to the WAN It’s what a local uh device a node on the local area network needs to go to this default gateway And finally we defined the two custom IP address schemes The one which allows me for variable subnetting and the other cider which allows me to use a slash and then put a number that number representing the number of network bits in the subnet mask Right So the most popular of course 24 would be for a class C 16 would be for a class B and 8 would be for a class A because if we had a /8 that would mean the subnet mask is 255.0.0.0 data delivery techniques and IPv6 Now we’ve talked a lot about IP addressing when it comes to IPv4 or the Internet Protocol version 4 but fairly recently IPv6 or IP or Internet Protocol version 6 was released and has now begun to be implemented across the world in every network situation So in this module we’re going to discuss the core concepts that are involved with IPv6 addressing and some of the data delivery techniques as well So at the completion of this module we’re going to have a complete understanding of the properties of IP version 6 or IPv6 and we’re going to be able to differentiate between IPv6 and IPv4 which is the one we’ve been talking about up until this point As a reminder IPv4 is that IP address that is 38 bit uh 32 bits and divided into four octets And we’re also going to outline some of the improvements in the mechanisms of IP version 6 and why we needed to have another version of IP addressing We’re also going to cover the different data delivery techniques uh as well as what a connection is different connection modes and we touched on these briefly such as connection oriented and connectionless and their transmit types Finally we’re going to go further into data flow or flow control which we’ve talked about a bit and we’ve mentioned a bit buffering and data windows These are all uh techniques that allow data to be sent over a network in varying ways And finally uh also we’re going to talk about error detection methods That way we know when data arrives on the other end uh we can doublech checkck it to make sure it is the data that was in fact sent So in the last module we learned about the IPv4 addressing scheme and we talked about some aspects of how it’s implemented Now IPv6 is the successor to IPv4 and it offers a lot of benefits over its predecessor The first major improvement that came with this new version is that there’s been an exponential increase in the number of possible addresses that are available Uh several other features were added to this addressing scheme as well such as security uh improved composition for what are called uniccast addresses uh header simplification and how they’re sent and uh hierarchal addressing for what some
would suggest is easier routing And there’s also a support for what we call time sensitive traffic or traffic that needs to be received in a certain amount of time such as voice over IP and gaming And we’re going to look at all of this shortly So the IPv6 addressing scheme uses a 128 bit binary address This is different of course from IP version 4 which again uses a 32bit address So this means therefore that there are two to 128 power possible uh addresses as opposed to 2 to the 32 power with um IP address 4 And this means therefore that there are around 340 unicilian I’m going to write that out So that’s a word that you probably haven’t seen a lot Un dicilian addresses And to put that another way it’s enough for one trillion people to each have a trillion addresses or for an IP address for every single grain of sand on the earth times a trillion earths give or take a bit So if the 128 bit address were written out in binary it would be 128 ones and zeros because that is binary And even in decimal form that’s uh pretty hard to read and keep track of So because of this we use what’s called hexadesimal as the format in which uh IPv6 is written And if you imagine from the name hex uh binary is a base 2 system meaning that we take everything to the power of two So we have the ones place and then we have the two place and then we have the four place and so on and so forth with decimal which is a base 10 system we have the ones place the 10’s place the hundred’s place which is 10 * 10 the thousand’s place and so on with hexadimal though we’re looking at a base 16 so every single digit has a possible 16 different options so we’d have a ones place which we always start with a ones place and then a 16’s place and then so on and so forth Now the way we do this is that every digit as opposed to decimal where we have 0 to 9 options for every digit and binary where you have either 0 or one with hexadimal we can either have 0 to 9 or a through f If we add this up we have 10 options here 0 through 9 And then A through F we have six So a hexadeimal number is going to be a combination of anywhere from 0 to F Uh A would be 10 B would be 11 C would be 12 and so on and so forth So when you see uh this written out that’s what that means Okay Now the address is broken up into eight groups of four hexadesimal digits and these are separated by colons Now uh I’m going to show you this in just a second but there are also a couple of rules when it applies to when we come to readability So the first rule is that let’s say this is our hexadesimal IPv6 address You notice first of all 1 2 3 4 5 6 7 8 Right There are eight groups of four hexadesimal digits each And of course each one of these digits has 16 possible values Okay So let’s look at two rules And these are also not only readability rules but what we call truncation rules Meaning this is how we can shorten an IPv6 address since they can get quite long The first rule is that any leading zeros can be removed So if we imagine any leading zeros I’m going to circle them right there right here right here And if we wanted we could even consider these leading zeros And therefore if we rewrite this out below you’ll see we’re going to remove all the leading zeros And that allows us to shorten our um address Now we could also if I was just going to take this one step further I could also shorten these zeros if I so wished and just leave one zero there Now no matter how you write out the address the rules are put in place in a way that you can always go back to the main address And so uh you don’t have to worry about you know you can sort of pick and choose There are best practices but the computer’s always going to be able to figure it out Okay Now the second rule is that successive zeros or successive sets of zeros can be removed but they can only be removed once So any sets of successive zeros and here we see one set or two sets rather success of zeros can be removed and replaced with a double colon Now the reason we can only apply that once is let’s say these zeros were we had another set of zeros over here and we um truncated those we can add up right we know there’s one 2 3 4 5 six sets here so we know that this represents two sets of missing zeros but for instance if we had you know two other sets here and we remove those We might not know whether it’s supposed to be one set and three sets or two sets and two sets and so on and so forth So we can only do this once because when we add them back there’s no way to know um uh you know where that would sort of lie Now uh I’m just going to erase this for a second because we can even truncate this more We’ve applied this rule So this applies this rule This one has applied this rule But we can apply both rules right So we can remove these leading zeros here and actually write this out as 2001 D8 88 A3 double colon which means that those are successive zeros 3 e 70334 Now let’s just I just want to uh sort of follow up and explain write out what I was just talking about with why we can’t have more than two sets of successive zeros Okay let’s say that we have zeros here as well Okay so I’m going to rewrite this out We have 0 0 0 colon 0 0 0 colon 08 a3 colon 0000 0 8 c 3 e 00 070 7334 Okay let’s first apply our first rule which is that leading zeros can be removed So we rewrite this and we’re going to get this Okay Now we’re allowed to remove one set of leading of successive zeros only which is the second rule Okay But let’s do it twice and just see what happens So let’s say we we have a double colon here 8 a3 and then we have another double colon 8 c3e 7 0 7334 Now let’s say we want to expand this back out to its full version Well if we have these successive zeros here we don’t know if this would be written out 0000 83 because from what we’re seeing here theoretically we could put three zeros here and one zero here right Or we could do it the other way around So the reason we can only do it once is because then mathematically we know exactly how many belong when we do that All right So hopefully that helps clarify the reason behind the success of zeros being removed All right Now uh what this also means is that if you remember a loop back address an IPv4 the loop back was 127.0.0.1 Well we also have a loop back when it comes to IPv6 That’s all these zeros to one But because we can apply all of these rules we can truncate this to simply this All right So uh this is important to remember These rules are important to remember The other thing I want you to remember is that hexadesimal is 0 to9 a to f So they might show you something and say which of these is not a valid IP If it has a letter say a G or an H then you know it’s not going to be valid And here we can check Here’s a D that’s good Here’s an A that’s good C good E good So this is good to go Right If we had an H or a G or an X for instance then we would know that the um uh IPv6 was incorrect because there’s no hexadimal symbol X So the IPv4 addressing method is is really different from IPv6 addressing and it’s comparatively it it’s lacking in many areas First as we’ve talked about we’re using a 32-bit binary address in IPv4 versus a 128 bit binary address in IPv6 And of course this greatly increases the number of possible IP addresses Uh I think around February of 2011 all of these IP addresses had been leased and uh so there weren’t any addresses left I think we had something at like 4.8 4.7 billion right Right And all those were gone And so we were depleted of all of our IP addresses So this is why we had to transition to IPv6 because now we have that undecilian uh address which again is if every there were a trillion people they could each have a trillion addresses Now another major difference between these two is that uh IPv4 utilized the classless interdomain routing notation if you remember which had that slash and then a number of bits Well in IPv6 this isn’t necessary and IPv6 actually has a subnet size of 2 to the 64th power Now if you remember that the total IPv6 is 2 to the 128 then what you realize is that the first half of the IPv6 address so if we were to write one out again let’s say uh 208 a 364 uh 9 2 F 1 0 0 0 right okay so then we’re going to have four more on this side the first four which again is the first 64 bits that’s the subnet so now we’ve integrated the subnet into the IPv6 address which is the benefit now we don’t have to sort of have this extra uh uh written out CI thing so it’s been standardized it’s always 2 to 64 we always know the subnet or the network node is on the first section and the node ID is on the second the second section the other two to the 64 So this really help helps us simplify things to a great extent Now obviously one of the issues is we’re going to underuse uh a lot of the addresses We’re going to underuse many of our addresses because we’re never going to have to really use this many subnetss or perhaps not even that many networks right But um there are so many other benefits that it has with routing and efficiency and simplified management that it it sort of um makes up for it And so that’s why we’re going to make that sacrifice Now in terms of domain name systems uh with DNS when we talked about for instance a google.com going over to say you know whatever that IP address is and I’m making this one up obviously it’s not a real one because we’re in a private IP but this was called an A record right so a server would have something or a DNS server would have something called an A record and that a record had this information in it All right Now when we’re dealing with IPv6 we’re utilizing a quad A record for this mapping Now it can also use the same A record but this quad A record can be used as well So if you see 4 A’s what we call 4 A record or quad A record then you know we’re using IPv6 It’s one of the differences And again these are the records that are used to map IP addresses to what are called fully qualified domain names Now while comparing these two schemes also IPS which stands for IP security is another aspect that we need to consider In IPv4 IPSec is optional it it’s widely used for uh secure traffic over IPv4 communications but when we dealt with IPv6 IPSec was designed for it and so uh it’s required from the original specification and therefore all communications that are working over IPv6 are automatically falling under IPS so it can be considered in some ways optional I guess But um it is required use from the get- go because it was built into IPv6 Now the IPv6 scheme can also handle a much larger packet size The packet size for IPv4 is 65,535 octets payload When we get to IPv6 we’re dealing with a 4.295 billion octets of payload So obviously these are a lot bigger These are what we call jumbo grams As a result you can imagine that if we want to deal with IPv4 and we’re on an IPv6 network we’re going to have to make up for this Now if you recall when we were talking about Ethernet we also were talking about the header sizes and all the information that was contained in there Well the header size for IPv4 and IPv6 is also very different which actually makes these two um protocols not compatible with each other So IPv6 is not compatible with IPv4 And so the way we’re going to communicate with an IPv6 over an IPv4 network if we need to is by tunneling the packets In other words we take an IPv4 packet I mean an IPv6 packet and we literally wrap it around or we wrap around it an IPv4 packet and so we tunnel the IPv6 packet inside of the IPv4 Now this allows it to communicate but this is also what we call a dual stack uh in some cases we can have what’s called a dual stack where we have an IPv4 and an IPv6 and so we can choose which one to go over and then this tunneling is not going to be necessary Now we don’t really want a tunnel because obviously the payloads are so much different in size that it’s going to cause all sorts of trouble So what we’ll try to do is create this dual stack in which we have one network and the other and they’re both operating sort of side by side If we can’t do that then we have to use tunneling in order to move the IPv6 data over an IPv4 network which might be necessary even if the IPv6 data is traveling through an IPv4 network All right so we’ve compared these Let’s talk about some of the improvements that IPv4 did not have that IPv6 does Uh starting with some security and privacy measures If privacy extensions are enabled with IPv6 then we have something called an ephemeral address which is created and this is used as a temporary and random address that’s used to communicate with external devices but the external device doesn’t know the true address of the internal device And so this improves the the privacy and security for the user and this is what we call a privacy extension and it does have to be uh enabled from sort of a router point of view Now another improvement is a better composition of what we call the uniccast address What this means is that IPv6 uses a uniccast addressing structure to replace the classful addresses of IPv4 Uh this offers a lot more flexibility and efficiency with addressing and depending on the category of the uniccast address used there are different functions for each meaning that there are different types of addresses that are used and that way the computer automatically knows what the function is The first is called a global address which is sort of like the public or routable addresses uh in IPv4 If you recall most addresses could be routed Those are what we call global addresses We also have site local addresses which are essentially like the private addresses or nonoutable addresses that are not routable to external networks If you recall these were for instance the 10.0.0.0 through 10.255.255.255 and then the 172.16 through32 and then the 1 192.168 Those are the private addresses Well in IPv6 we call them site local addresses We also have something called link local addresses which are basically comparable to uh a peepa addresses in IPv4 and we’re going to talk more about what those mean in just uh a little bit later but just to to give you a little heads up and we have talked about it with uh uh A+ if you around for that This is automatic private IP addressing and we need because every device needs an automatic IP address If it’s not given one by a server then it’s going to give itself one what we call an APIA address And so in IPv6 these are called link local addresses And finally there are IPv6 transitional addresses which are basically going to be used in the time being until we phase out of IPv4 uh these are used to route IPv6 traffic across IPv4 networks through tunneling much like I’ve just described in the previous uh section Now a mechanism uh built into IPv6 addresses is a field located in the IP header that’s designed to guarantee network resources be allow allocated to services that need time-sensitive data such as voice over IP Right We need that that is time sensitive because I’m talking and I want the person to hear almost as soon as I talk And so this timesensitive stuff is built into IPv6 one of the reasons that we use it Now another improvement with this scheme IPv6 is called hierarchical addressing This eliminates the random allocation of addresses Uh so connectivity devices such as top level routers are assigned a top level block of IV6 addresses and then segments are added to those with blocks of addresses that are assigned at that level So basically it looks like a hierarchy from an IPv6 standpoint You remember we looked at an uh this sort of topology earlier Now IPv6 scheme also has a much simplified header and it’s going to make addressing a lot easier to read This improves the speed packet routing on an individual packet basis So obviously if we’re going to simplify how information can get read it’s going to simplify how routing can occur Now data in transit is susceptible to a variety of things that could cause it to be delayed lost or damaged And these things can occur on the transmit side and quite commonly on the receiving side as well So the method the data is delivered makes a huge difference in whether the data is going to arrive at the destination correctively uh and efficiently So depending on the method of delivery there can be error detection which would mean we detect that they’re errors and error correction which means we not only detect but we fix the errors when these recovery mechanisms are used Now an important aspect of the data delivery begins with the actual connection itself So depending on the type of connection service used is going to give us an idea of what sort of delivery options are available So a connection in terms of networks is the logical joining of two network devices through a specified medium that is established and maintained for a period of time during which the session exists In other words the connection is what allows data to be transferred between say my computer and a server computer Now in networking and specifically in IP networks there will be connection services that attempt to provide uh data integrity and reliability Now there are generally three types of connection services that we see uh when we discuss certain protocols and we’ve talked about these in some way shape or form but it doesn’t hurt to sort of go over them in a little more specific detail The first is an acknowledged connectionless service In these the connection isn’t created However when data is received by the destination there is a acknowledgment of receipt Uh so website communications use this type of service A great metaphor to think about this would be for instance a delivery receipt with regular mail So it’s not certified We’re not going to get a signature but what we do is we get a receipt that it has been delivered Now with unacknowledged connectionless services there’s no acknowledgement sent unless the application itself does this This could also be considered simplex communications which we’ll talk about in just a second So this is just like regular mail We send it we drop in the mail there is no acknowledgement Okay acknowledged at least has uh an acknowledge that data has been sent but there is no connection made right there is no established session made between the receiver and the sender Finally we have connectionoriented services And by the way when we talked about these connectionlesses you recall this is like UDP which is connectionless and IP Here connection oriented we’re looking at TCP Now these are where error detection and correction are available as well as some flow controller packet sequencing In other words this would be like certified mail Now there are also three types of connection modes that we’re typically going to use There’s simplex half duplex and full duplex With simplex this is oneway communication only This is sort of similar to uh FM radio broadcast right You turn on your radio you tune in and you can receive but you cannot send data Now we also have half duplex This is two-way communication but only one at a time This is like a pair of regular walkie-talkies Only one device can transmit at any one time which is why we have to use those code words right Over over over and out So this is like a walkie-talkie Finally we have full duplex which is two-way and both ways simultaneously This is similar to the telephone in which we can talk and listen at the same time In some ways uh we have trouble understanding each other as a result of it Now in networking devices are designed to receive and transmit data at different speeds and with different sizes of packets as well So certain devices are not going to be able to handle as much data as others at one point or another We talked about this briefly with MTUs and MTU black holes So flow control is the managing of amounts of data and the rate at which the data is being transmitted over a network connection Flow control is necessary to help prevent devices from being overflowed with data Some devices when there’s too much data is received are going to potentially shut down to prevent certain attacks or simply are going to drop packets that are too large because they’re going to cause delays On the other side of the scale if too little data is being received by the device it may just be sitting idly by waiting for the remaining packets In this case it’s simply a matter of efficiency So there are two main types of flow control that are covered on the exam Buffering and data windows Buffering is a flow control technique where a portion of the memory either physical or logical via software is used to temporarily store data as it’s being received in order to regulate the amount of data that’s being processed Buffering may be used to maintain data consistency as well as minimize overloading Now RAM uses a type of buffer when data is being read from its cache right So remember we talked about RAM and that was what we called cache Now with buffering there is a potential concern because what if the buffer becomes full Well when receiving nodes buffer reaches a certain capacity it actually transmits a squelch signal I’m going to write that out just not only because it’s a great word that says stop transmission or slow down your transmission so I can catch up Now a common place we’re going to see this type of flow control is when we’re streaming movies You might have seen buffering when you’re using movies for instance on YouTube or on Netflix or any of these sites The idea is if there’s a problem with our communication we have a little buffer of data so that way we’re not going to see a dip in quality of the film Now another type of flow control is called data windows The data window refers to the amount of data being sent and it can either be a fixed amount or uh it can vary and these are fixed length windows or sliding vary sliding windows rather If you think about the window and I put the data inside of it we can either have a window that is a specific length like this or a window that can possibly get smaller based on the data And that’s what fixed length and sliding windows are So to go a little more in depth into these with fixed length windows the size of the packet of the data being sent is determined by the sender and the rate of transmission is determined by the receiver So the size is typically going to be pretty small and overall this is going to be fairly efficient The other thing to remember is that the packet size is always going to remain the same It’s never going to change So if I need to send 10 packets they’re all going to be exactly the same size or as much as I can draw them as such and so on and so forth Now with a sliding window method it’s a bit different The sender begins to transmit data typically with a small number of packets and with each transmission it uh waits for an acknowledgement or act packet receive Now with each receipt this contains the current maximum threshold that can be reached And then the transmitter is going to begin increasing the number of packets by a specified amount In other words it’s going to start sliding that window from here over Now it’s going to continue to increase this over and over and over until we reach a maximum potential At this point we’re going to start getting some congestion And so the receiver is going to send another act saying “Listen you need to slow down now.” And and and this is a good rate This method is really going to allow for minimal data traffic congestion and a lot of throughput And depending on the amount of traffic the size of the window can really vary dramatically And so this really gives us a lot more flexibility If you imagine if I have a home that has a whole bunch of regular windows I’m going to want sliding windows Now if I have a home with all these similar windows everything built the same then I can use a fixed length window But this one’s going to give me a lot more flexibility Now error detection and correction is an important aspect of how we know our information arrived at the destination unhindered and unaltered One method achieves this by attaching supplemental information at the end of the footer that pertains to its contents and the receiving station is going to look at that data and compare it to the data it received If the data matches it’s going to consider it error-free If not the data is going to be requested to be retransmitted Now when an additional correctional component is added that allows the data to be rebuilt in the error uh in the event of an error this is going to become an EDAC or error detection and correction Now par check is a process where an extra bit is added to every word of data and the receiving station can look for the bit on this wordbyword basis Remember we’re talking about words We’re not talking about uh language We’re talking about words as far as data goes And so it can look at these and therefore it can determine any errors that are built in because par adds this extra bit to every word This method takes a little bit of overhead So it does add not only extra resources but some more data in there Now with something called CRC or cyclic redundancy check a code is added to every block of data through a mathematical operation which is also referred to as hashing Now this code is added to the end of the block and then it’s transmitted when the receiving station applies this hashing method this mathematical operation to the code then it can should get the same data and if it doesn’t then it knows there’s a problem and it can request it to be resent like par CRC is also going to add a certain amount of overhead because it takes data and calculation time All right So now just to review some of the topics we talked about We talked about the IPv6 addressing scheme Specifically we talked that it’s a hexadimal 128 bits divided into eight sections We also compared and contrasted IP version 6 with IPv4 We saw that IPv6 for instance has IPSec built in and has a whole bunch of other improvements and mechanisms such as data delivery time sensitive and so on and so forth The important thing I really want you to know about IPv6 is that it does not require a subnet And we need to recall all of the truncation or readability rules which include removing leading zeros and combining successive sets of zeros but only once We also explained the different data delivery techniques and we defined a connection the different connection modes whether they’re acknowledged connectionless simply unacknowledged connectionless or connectionoriented We also looked at the different transmit types including simplex which is one way half duplex which is like our walkie-talkie and full duplex which in effect doubles our bandwidth We also explained flow control buffering and data windows We use buffering a lot when we’re talking about videos In data windows remember we talked about the fixed and sliding windows Finally we outlined error detection methods including parody which adds an extra bit to every word and CRC or cyclical redundancy check which uses hashing a mathematical operation so that we can ensure the data that was received was also the data that was sent Now we actually covered IPv6 earlier However as per usual some new uh ideas been added to the syllabus So what I’ll do here is I’ll uh review some areas that you’ve already covered with Josh uh just with my own take and then we’ll go into the new stuff So IPv6 addressing address types new is a neighbor discovery protocol which is part of IPv6 builtin Uh the EUI 64 addressing is new Tunneling types is new So IPv4 which is obviously the precursor to IPv6 uh created a long time before we had home computers The computers were pretty expensive and big probably the size of any room in your house So no um no nobody foresaw that people would be using uh home computers just like when the telephone was created I think uh one of the first comments was why would I why would I need to phone anyone So uh there we go Uh so it was just the scheme was designed just to c cater for commercial enterprises only So we didn’t think we were going to run out uh lack of a simple auto configuration mechanism So eventually we had um DHCP was uh created uh which works well Obviously it’s got some drawbacks IPv4 has no security built in Again nobody realized that uh well there was no such thing as hackers obviously when IP was brought out because it hadn’t been invented yet so nobody thought that we needed to have it built in IPv4 is hard to use with mobile devices especially uh when we’re using the cellular networks Uh IPv4 needs massive routing tables required over the internet Internet service providers have huge tables for routing all the IP traffic Uh there’s only around 4 million addresses available We actually ran out of IP4 addresses some time ago and around 50% of the traffic going over the internet at the moment is IPv6 which is why we need to know about it So IPv6 uh there’s that many addresses I I don’t even know what the numbering system is called for calling out that many but for every person uh alive there’s many millions of available addresses Now NAT can be used with IPv6 and you’ll read some documents about NAP PT Not really used um there’s no need to because there’s just no shortage of addresses really Security is built into one of the fields in the IPv6 packet We have address uh auto configuration which um is a a major part of IPv6 and it’s plugandplay as well So things like when you enable IPv6 on an interface with most uh devices now uh it actually self-configures an IPv6 address We do not have broadcast on IPv6 We’ll come to that later Uh it’s built to work plugandplay with mobile devices again which is handy So the address is there’s several RFC’s One of the main ones is 1884 if you want to read it It’s 128 bits Each of these bits is divided into into eight groups of 16 bits And then each of those bits is uh separated by a colon which is a a dot on top of a dot Hex numbering is used because it’s just a lot easier to uh write out that many bits using hex than it is in um binary It would take forever The addresses when you’re typing them out at interfaces is not case sensitive So you could use caps lock or lowerase and the address will work fine and be accepted Here is an example of an IPv6 and you can see if we just come over here So eight groups of 16 bits which you’ll go into into a minute Uh divided here by the colon and another uh 16 bit 16 16 and so on So if you wrote the uh address out in binary just for the don’t know why I should have said D here sorry E D E E D E but uh if you change the hexadimal here so this is the hex into the binary value it’s one in the uh if I go one two I know you already know how um binary works Four eight So one in the eight column one in the four one in the two So 8 + 4 uh is 12 8 9 10 11 12 13 14 So the E uh is number 14 here Uh 14 here in hex Now we’ve got the D So we’ve got uh 1 + 4 + 8 So 8 9 10 11 12 13 So D is 13 And then we’re back to another 14 16 bits two bytes in total So four bits uh four bits eight and then another eight 16 bits So that’s two bytes We can compress the address So you can remove the leading zeros Leading zeros are uh numbers that appear before So this is a leading zero Leading zero This is a trailing zero So we can’t uh remove these because they’ve got numbers uh prior just before So if we get rid of the leading zeros for example here 0 01 becomes a one 0789 becomes 789 And this is there to save space And for when we’re writing out the addresses 0 ABC becomes ABC And you can get rid of the trailing zeros here and just have one zero So this address is uh legal to write that out You could possibly have questions in the exam uh asking you to choose the correct compressed address You can use a double colon once to represent consecutive zeros So here we go We’ve got all these consecutive zeros here for some reason or we’ve got rid of them just by having the double colon here And we’ve got a double colon here between the 1 2 3 4 So what we’ve done is just compressed all of these zeros and we’ve done it again here and then just to we could have put it in the second set of zeros but just to save space we’ve got rid of all these zeros here So practice this uh work out your own numbers because this is a typical exam type question Main IPv is uh six address types global uniccast unique local link local and multiccast You’ll note we don’t have broadcast That isn’t a legal address And we also have anycast which I’m not sure if I mention here So the global uniccast the allocated by the ISP and then you will get a mask associated whatever the mask may be These are routable on the internet So you can send them out of your company and um they’re legal They’re legally recognized The numbers range from 2,00 to 3 FFF in the first 16 bits Current allocation there There’s trillions of these addresses So the current allocation has come in from 2001 This will this will last quite some time Obviously there’s a 48 bit provider prefix and if you u check the images of the uh address packet you’ll see the 48 bit uh there’s a subnet ID you can subnet inside the organization if you wish subnet in IPv6 is a topic but it’s not in the compia it is in the Cisco CCNA and then the rest is the host portion of the address Now I’m I’m sure most equipment can actually do this but Cisco routers can self-generate this part here So what you would do is if you configure an interface you would you would basically configure whatever the address is b whatever whatever then the host portion here uh the interface would um self-configure So um I’ve issued oh this is on my um Windows computer by the looks of it I’ve just issued an IP config all for/all and I’ve seen the IPv6 address that’s been allocated here Uh I think Windows selfallocates these addresses also uh link local address The prefix for link local addresses are FE80 These are only valid between the link between two IB6 interfaces So you’ve got an internal router and say for example an Ethernet connection here Then these addresses will be valid and these two IPv6 routers can communicate with one another using this link local address What it can’t do is this address in here it can’t be used to reach another device out here Now if you’ve got another device the link local addresses of these two M facing interfaces So for example fast Ethernet here fast Ethernet here they will communicate between one another here Automatically created once IPv6 is enabled Now these are used for routing protocol communications IPv6 protocols mentioned in the syllabus but I don’t think I’ve left it out for now because looking at all the official guides there’s no um questions yet I will add it later on if um if that changes though Traffic isn’t forwarded off the local link Certainly not using the link local address So here’s a configuration for a Cisco router you I’ve enabled IPv6 routing I’ve gone to the fast Ethernet interface All I’ve done is turned on IPv6 for this interface here the fast ethernet 0/z I’ve typed end and then it I’ve said show me this interface It’s down I haven’t connected it to anything But as we can see this address this link local address has been allocated selfallocated This is an important bit here FFE as you’ll see in a minute but basically this is my IPv6 address I haven’t had to write it out manually at all I’ve already um shown you the Windows one Yeah Unique local Uh it’s a IPv6 version of private IP addresses So you can use all of these uh on the inside of your network You wouldn’t be able to route with them onto the internet Don’t think these are used anymore I think they’re actually been depreciated Uh if you get a question in the exam here it would be something like this What prefixes link local addresses taken from FC0000 uh slash7 for your subnet mask These depreciate site local addresses are sorry So it’s site local addresses that have been depreciated um overtaken by link local a unique local So you’d use this on the inside of your network if you want to do any internal routing What you couldn’t do is use it out on your on the internet though Multiccast addresses are still used very much in IPv6 This is the uh prefix So write it down and put it into your study creme notes And multiccast replaces address resolution protocol for IPv6 A use for duplicate address detection So when you first uh fire up your interface I’ll talk about neighbor discovery in a moment but I’ll say just to save space I’ll say this is the address Obviously it would be the IPv6 address It will this interface will advertise out this address to um the network uh this multiccast address saying I want to use this address X and if any of any other of these interfaces are using that address So this is using Y that’s using Zed It will come back and say no you can’t use that address But in this case my example here nobody’s using it All routers must join the all host multiccast group of FF02 and then whatever in the middle uh one So it’ll all be zeros and then one And the all routers multiccast group This is how neighbor discovery protocol works So it must be allocated and listening to these two addresses And if I issue a show ipv6 interface fast ethernet0/z you can say you can see that it’s joined these two groups up here the um the f2 and the f1 eui 64 addressing is the new part in the syllabus Uh so I’ve issued a show ipv uh IP interface Sorry I’ve didn’t do IPv6 because I want to see what the MAC address is because this is how EUI 64 obtains the um uh EUI 64 address So this is how or one of the ways it can self generate an interface It uses the MAC address the 48 bit MAC address Obviously we need 128 bits 48 bits isn’t enough to generate this address But what it does it takes the MAC address uh it inverts the seventh bit and adds FFE in the center So right in the middle of the MAC address it’s going to add FF Uh make sure you take a note of this uh for the exam So uh we’ve got 0011 I’ll cover why it doesn’t say 0001 one here and then uh here’s the AA here and then you can see the FFE has appeared here It’s inserted it and then it carries on with the rest of the MAC address BB CC DD so BB CC um CD So this is how it pads out the address So there’s two bits MAC address plus this but then it does this other bit here which is inverting the seventh bit So just to recap what I’ve already said we’re looking at this part now 0011 Well instead of that now we’ve got 0211 All right So going on to the seven seventh most significant bit So this is our sample address here The first two nibbles uh or is one bite So this is 0.0 So a nibble if we have one 2 3 4 5 6 7 8 So eight bits is one bite which we’ve covered already Whoops One bite one bite eight bits But what we can do is kind of subdivide it in the middle here And we can have a nibble here and a nibble here All right So our first two nibbles one bite here is 0 0 which would have all the binary bits basically pretty easy to work out So this here if you write it out with a nice uh font is 0000 0 So what we need to do is flip the seventh most significant bit So what we’ve done is 1 2 3 four five six 7 8 So this is the seventh most significant bit And what we’ve done is gone all the way over here to find the seventh bit and we’ve flipped it So whatever it was here in binary we’ve flipped it So one flip to uh sorry zero flipped to be a one Now if you wrote that out uh this part here you’d have um your zero would become a two That’s the 1 2 4 8 1 2 4 8 Okay So we’ve uh enable this column here and our zero has flipped to A2 And you can see here 0211 and then um this was the MAC address We’ve got the FFE in the middle and then the rest of the MAC address This is how you work it out You might get a question on this So this is why I brought it to uh your attention and you just need to practice a few examples So what would this address be changed to If you write it down All right So I’ve just carried it over to the next slide here So show IPv6 interface We’ve got this address here and we end up with this global uniccast address here And you can see already we’ve got the FFE created here So and because it’s it might not show you in other um vendors but you can see here there’s a clue It says EUI So we know EUI 64 is addressing Well C2 in decimal is 1 192 or um in binary here uh 1 1 0 0 double one 0 in hexadimal is C And if you’ve just got a one in the uh two the two column here So 1 2 4 8 You can see uh that’s a two C in um hexodimal is 12 So we’ve got 8 9 10 11 12 So I think we’ve covered hex earlier So you swap the seventh bit So 1 2 3 4 5 6 7 This bit has to be swapped If we’re doing EUI 64 and then it becomes a zero If you work this out 000 the second part is uh C 0 So here we go C 0 and then it carries on as normal 0 0 instead of C2 So I know it’s a lot to get your head around Just practice it Watch this over a few times and then practice some of your own examples Applying it Enter your desired subnet and then add the command the tag EUI64 This is how you do it in Cisco You won’t be asked about vendors or how to apply it I’m sure I’m just telling you how it works So I’ve added this address I want to say we’re using um this uh subnet here this address and uh double colon So I don’t care what goes there 64 and then I add the tag basically saying you um u allocate uh using the MAC address plus the uh seventh bit rule which will swap the seventh most significant bit from a zero to a one or a one to a zero And here’s the command on an actual router So you you have to you can’t just say create the entire address for the routable address Um you have to add this tag here All right Next is the neighbor discovery protocol which is a major feature of uh of IPv6 This allows other routers on the link to be discovered There’s a couple of messages you you need to be aware of which is RS router solicitation like are any routers on the link This is the router solicitation message and it’s sent out saying what what else is here The router advertisement is the reply you’ll get from the routers IPv6 routers a yep I’m here a I’m here It discovers pre prefixes So whatever your prefix is on the network etc These routers will say we’re using this prefix and then this will be able to autoallocate an address so it can comm communicate on the subnet So this replaces ARP We don’t have AR working on the uh on IPv6 subnets also works with duplicate address detection which I’ve already mentioned The device the IPv6 IPv6 device will say I want to use address X Are any of you using it And then there’ll be a reply if it is in use So neighbor solicitation asking for a neighbor’s information The neighbor advertisement you advertise yourself out to neighbors The uh solicitation ask for information about local routers These are the four types that you need to know about Router advertisement advertise yourself as active These are the four types So make a note of them DAD I’ve already mentioned the neighbor advertisements are sent to check if your address is unique This is the address it’s sent to which is the um same as the broadcast address but we’re multi we’re multiccasting in IPv6 No reply means your address is available to use The amount of air seconds should vary from vendor to vendor I haven’t read the RFC actually but if you really wanted to you can read it So you can see the advertisement is going out with this address Reply if you are this address using the ICMPv6 packet Um and then the advertisement here I am this address So basically you can’t use it DHCP version 6 is used for IPv6 This is for autoallocation of addresses Also used with uh it’s used in conjunction with DNS for IPv6 And here’s the RFC if you’ve got some spare time in your hands Allocates IPv6 information to host Obviously uh the IPv6 is um the gateway the D the DNS server uh and and other DHCP information Host can request it with an outgoing router advertisement message Allocated requested using UDP Bear that in mind because some people think it’s TCP It’s port uh 546 and 547 The other subject you need to be aware of now is if you’re running uh IPv6 on your network and then IPv4 nobody is going to come into work one day and have IPv4 uh taken off and only running IPv6 You’re going to have a transition period where you’re running both of these protocols So what’s going to happen is somehow IPv6 host reaches an IPv4 router And what you’re going to have to do is tunnel the IPv6 uh information inside an IPv4 packet with a header and uh the trailer running IPv4 There’s a few versions ISOTAP uh 64 tunneling Dual stack is when you’re running both at the same time There’s a static tunnel I think Yeah that’s different to GRE You don’t have to know the config so don’t worry about it Generic routing encapsulation has been around a long time but you can use that for tunneling Automatic as uh another type you can choose from If you want to study more I recommend everyone needs to do about uh four hours studying to IPv6 This is for interviews uh technical jobs uh technical interviews and just to do your day-to-day job You do need to understand it There’s a course on um how to network.com It’s 16 hours in total but I broke it down into I think the be beginner course is about three There’s an intermediate with loads of routing and then maybe I think five or trying to do my math now 6 to 12 7 hours extra which is advanced So you could just do one part and then when you come to do something a bit more difficult do the second part and if you want the third but u you really do need to know IPv6 I’ve been talking about this for about four years now and it’s becoming more and more urgent So you I used to recommend it and now basically the the level of uh understanding and the the level of adoption is basically you you have to know it It’s just like not knowing IPv4 now if you go into um if you go into an interview So please do learn it Uh we’ve covered IPv6 address types neighbor discovery EUI 64 and then tunneling That’s all for now Thanks for listening IP assigning and addressing methods So having discussed both IPv4 and IPv6 and the difference between these different types of IP addresses we now want to talk specifically and in more depth about how IP addresses are assigned to a specific node or client or server So in this module we’re going to look at the two different ways that IP addresses are assigned This involves defining the first static IP addressing Static meaning that the IP address is always the same and dynamic IP addressing which means that the IP address can change We also want to talk about the strengths and weaknesses of each of these addressing methods and we want to compare the features of one and the other We’re also going to identify when we want to use dynamic IP addressing as opposed to static IP addressing and define when we’re talking about dynamic IP addressing the terms DHCP the server and protocol that are responsible for allowing dynamic IP addressing to work Something called the scope which lets the DHCP server know which IP addresses are up for grabs And then the lease which just like the lease on an apartment uh lets the both the server and the client know when a uh IP address can be used and for how long We also want to talk about when static IP addressing would be preferred And as you can probably tell from the way this is worded we generally want to use dynamic IP addressing as we’ll talk about But there are certain instances in which a static IP addressing is the uh best method for us and we’ll talk about those as well So first let’s talk about static IP addressing It’s done manually and that’s what this really means Static means manual assignment which means that I literally have to go to the computer and type in what the IP address is and how I want to use it So there are two major flaws with this First it can be very time consuming because it has to be done manually and each address has to be entered individually by hand In addition this takes a lot of time and it’s prone to a lot of errors Uh human error is often a factor when we’re configuring addresses for a large amount of systems And if you can imagine I’m working in a system of say uh 5,000 computers then I’m going to be typing in IP addresses a lot Now while this may be a worthwhile method when assigning a very small amount of addresses it’s obviously not very practical when I’m talking about large quantities And the other major flaw is that it has to be reconfigured every time the address sync scheme changes So for instance if I was going from IPv4 to IPv6 on my internal network I’m going to have to rechange everything once I’ve switched over Or let’s say I want to change my naming system Maybe I want to go from a class C to a class A IP addressing system if I’m on IPv4 And in this case I would have to then reconfigure everything on each computer And you can imagine the amount of time that that’s going to take So due to its many flaws we’re really not going to use this method uh static IP addressing which means again manual assignment The way you can remember that is that static does not change right It remains constant And the word static meaning not changing is what tells us that So we’re only going to use that in specific instances And I’ll talk about that a little bit later So as a result it’s very rarely used except in very specific instances I’m guessing you’ve never had to enter the IP address on your SOHO router or at your computers at home And that’s because we’re going to use this other method being dynamic addressing Now as the name dynamic implies the IP address can change which means that it is automatically assigned Now this is a lot more useful of the of the two that we have for many reasons It’s done automatically through a a protocol called dynamic host configuration protocol or DHCP So you ever hear DHCP that is what is referred to when we’re talking about dynamic IP addressing This is part of the TCP IP suite and it allows a central system to provide IP addresses to client systems Now since it’s done automatically there’s no possibility of human error and it’s also a lot more efficient than static IP addressing As a result it’s a lot more common of a method Uh it also eliminates the need to reconfigure a system if the addressing scheme is changed So it’s far more commonly used because of all these reasons Like we just said it’s more practical and more efficient because I don’t have to change every computer All I have to do is tell the DHCP service computer we’ll talk about that in a second that we’re changing everything and all the underlink computers automatically are going to change So if we move over real quickly into our Windows system and let’s go into our network properties and we’ll go ahead and go to change adapter settings I’m going to rightclick on this and go to properties Now we’ll see over here if I click on TCP IP4 and go to properties it says obtain an IP address automatically So through DHCP the IP address is being automatically obtained just like DNS is also going to be given out automatically Now if I wanted to do it statically I would have to manually assign an IP address a subnet mask and a default gateway for each device So you can see where we’re not going to want to do that So let’s talk a little bit more about DHCP or the dynamic host configuration protocol This is the protocol which assigns IP addresses And it does this first by assigning what’s called or defining rather what’s called the scope The scope are the ranges of all of the available IP address on the system that’s running the DHCP service And what this does is it takes one of the IP addresses from this scope and assigns it to a computer or a client So for instance let’s say that we’re dealing for simplicity sake with a uh 1 192.168 class C network So the scope might be something like 1 192.168.1 10 through 254 This means that of the IP addresses it’s going to assign it’s not going to take anything in front of the 10 So this gives us 1 through 9 to use for static IP addressing So what this ensures is that the DHCP server is not going to assign an IP address that we have already manually or statically assigned to another device We’ll talk about why we would want to do that in a minute But this ensures again that the scope uh that the DHCP is not going to assign an IP address outside of its scope Then what it does is it takes this available address and assigns it to the client for a set amount of time and this is called a lease So the lease says how long the IP address is going to last Now the reason that we had leases is because remember if I turn off my computer it no longer needs an IP address It also means that let’s say I’m taking a computer away uh I don’t if I have a if it has a lease of forever then that computer now has one of my available IP addresses So sometimes we’ll have an IP address with a 24-hour lease or maybe a 2day lease But whatever that lease is at the end of that lease it’s going to have to re again ask for another IP address This is also the way that we can share a limited number of IP addresses with a lot of uh computers or nodes So when we had the internet we used to dial up to the to our ISP or internet service provider What this would allow is it allowed our uh ISP to provide us with one IP address that only lasted for a certain amount of time and then when we disconnected the IP address or disconnected from the server and therefore it didn’t need the IP address it could assign it to someone else and it didn’t have to worry about us coming back on and wanting to use the same IP address because remember one of the rules is you cannot have two devices devices with one IP address All right Now let’s talk about how this works from the client’s point of view Basically what happens is I have a DHCP server here and it has what’s called a trusted connection to the switch We’ve defined what a switch is previously and we’ll talk a bit more about them later as well but it has a trusted connection This computer say comes online and says “Hi can I join your network Can I get an IP address?” It sends its request through what’s called an untrusted connection to wherever the DHCP server is Now the DHCP server at some point finds this because this is generally a broadcast because again it’s not a uniccast it’s a broadcast because this computer coming on doesn’t know where the DHCP server is So it sends a broadcast message out the DHCP server then responds and offers a lease on an IP address at which point this untrusted or unassigned connection becomes a trusted one Now when the lease goes out it’s again untrusted and so it needs to repeat the entire process again Now so far we’ve been pretty fair to DHCP and expanded on the benefits for dynamic addressing but there are some exceptions when a network is configured uh for DHCP and we don’t want every single device to be automatically assigned an IP address For instance um the DHCP server itself needs to have a static IP address This is because we don’t want the DHCP server to be changing addresses And what’s going to happen is if we have a lease theoretically the DHCP server could change its IP address And since every computer on the network needs to know where to go that’s going to have to remain the same This is going to go the same with the domain name server So the DNS server which allows us to convert between say google.com and the IP address So we don’t want to have to find this every single time and we have to set it as something specific meaning static We’re also going to put our web server as some static IP address This is the reason why if you wanted to uh get an account with your ISP or internet service provider and you wanted to run an web server from your computer at home you would need to ask for a static IP address because that’s the only way that someone can link through DNS to your web server And so our web servers always has to be static because when I type in google.com I always want it to go to one of a few different IP addresses Finally printers are something else that we want to have be static because the printer we don’t want to move around We want to be able to lock it in when we install it on the computer Uh same with any servers also routers the gateway computer or the gateway device that allows us to get out to the network We need that to remain the same So that’s why when we define the scope and in previous example we defined it as any IP address between 10 and 254 we don’t want it to change because we want these nine IP addresses to be ones that we can assign Now sometimes we’re going to make this a little larger uh so that way we can assign uh a lot more static IP addresses So also maybe a web uh wireless access point we might want to be static etc etc And all of this again is done uh through a web interface or through um some sort of um router device or through a terminal or something So this is not something we’re physically hard wiring onto the device because again that’s that’s a MAC address physical address but this is something that we want to set through a software of some sort All right All right So just to recap what we talked about we defined static IP addressing Again static means that the IP address does not change It also means that it had to have been manually assigned Okay Now we also talked about dynamic IP addressing which DHCP allows us to do And this means that the IP address can change because it is automatically assigned One thing I didn’t specifically talk about what we referenced in previous modules too is that a pipa address that automatically assigned IP address which if the dynamic IP address system is not working so the DHCP server for instance is down and it can’t get an IP address from the DHCP server it’s going to assign itself its own IP address If you remember that was 169.254.x.x So if you see this is your IP address then guess what your DHCP server is down We also identify the strengths and weaknesses of each of these So um we define the static we define dynamic and then we identify the strengths and weaknesses of each Remember the strength of dynamic is that it’s easy and it requires less work if we change anything Of course the dynamics or the the downside of it could be this aipa or we don’t want um the IP address to change We also talked about when to use dynamic IP addressing which is in most cases We defined DHCP which allows dynamic IP addressing to work scope which is basically the range of IP addresses and the lease which is how long the IP address is going to be sent out for and then we recognize when static IP addressing is preferred for instance when we’re dealing with printers or routers or even the DHCP server itself which we cannot have change TCPIP TCPIP tools and commands So in the last module we talked about the simple services that TCPIP provides and those you may or may not see on the network plus exam However in this module we’re going to talk about some of the most essential tools when it comes to the TCP IP suite And I can almost guarantee you you’re going to see these on the exam So we’re first going to discuss and demonstrate all of the TCP IP tools And some of these tools include the ping command And some of these we might have seen previously as well perhaps in A+ Uh and some of these also I’ll go into the operating system and show you So we’re going to see the ping command which basically tests for connectivity We’re also going to look at the trace route command which basically uh traces a ping route And remember when we were talking about um uh protocols previously we mentioned the MP protocol the control messaging protocol and that is what a ping and a trace route command use or these types of packets So we’re also going to look at a protocol analyzer Uh not necessarily a command line tool but something that allows us to analyze the protocols uh or rather the packets that are going in and out of a um network or a system Look at a port scanner Sort of does the same thing We’ll talk about the difference between these two We’ll also look at something called NSOKUP And if the NS doesn’t ring a bell with you that is like DNS or name server lookup How we convert between an IP address and a fully qualified domain name such as Google We’re also going to look at the ARP command which allows us just like NS DNS which does a name to an IP address ARP is what is responsible for routing and allowed us to convert between an IP address and a MAC address or physical address So you can see where this is really going to come into uh into handy when we’re talking about routing and switches Finally we’re going to look at the route command which can present us with routing tables and is specifically more or less used when we’re dealing with routers not so much in Windows All right so first the ping command The ping tool and the ping command are extremely useful when it comes to troubleshooting and testing connectivity Basically what the tool does is send a packet of information and that packet again is MP through a connection and waits to see if it receives some packets back This is not unlike when you used to see the radar screens on a computer on a TV or program We’re talking bit with um uh submarines for instance and you would see basically a submarine here and you’d hear a ping coming off of that So it gets its name from that sort of sound So the data literally bounces or pings right back if there’s an established connection It can be also used to test the maximum transmission unit or the MTUs And remember we talked about that when we dealt with an MTU black hole which was in a previous lesson Now this is the maximum amount of data packets that can be sent over a network at any one time or the maximum size of that data packets So using this you can test the time it takes in milliseconds for data to travel end to end or to other devices on the network Now this can also be done on the local host and you remember the local host is 127.0.0.1 that’s the IP address for it And we can test this all by opening the command prompt and typing in ping and then the IP address So let’s take a look at this uh for just a second If we’re here and we have our command prompt and I wanted to type for instance ping 127.0.0.1 which would be the local host I can tell that my time is less than 1 millisecond which makes complete sense since there should be no loss of data It should take no time And you can see that no loss of data right here right Because we’re sending it there and back And obviously
we’re dealing with ourselves the local host or the 127.0.01 So it shouldn’t be an issue And if we do that notice that when I use local host I’m using um my own name and and it’s also giving the IPv6 IP address here Now if I clear the screen for a second I can also for instance ping google.com And you’ll see that it actually sends first It figures out what the IP address is and then sends that And it gives us the time that it takes to get there and back It also gives us some sub some statistics For instance it was sent four of them were sent four of them received zero lost And so we know that on average this is taking 13 milliseconds to get from us to Google And if you imagine that this was a local host uh or or rather a sorry a local uh server on my network and I was rebooting that server this could help me tell whether the server is back up again And one of the things I might want to do with that and I’m just going to use the local host right now is use the slasht um switch And what this will do is it’ll continually ping the same IP address over and over again Now I so for instance if I was waiting for a server to come back online this would be an easy way for me to tell whether it’s come back online or not and I could exit that by pressing controll C All right so the next one I want to talk about is trace route which actually goes handinhand with ping because it also uses that data packet or protocol It basically tells us the time it takes for a packet to travel between different routers and devices And we call this the amount of hops along the uh the network So it not only tests where connectivity might have been lost but it’s also going to test um the time that it takes to get from one end to the other end of the connection And it’s also going to also show us the number of hops between those computers So for instance between me and Google there might be four different computers And so each one of these is called a hop And we can measure how far the packet is traveling before it gets back to us Now I can also use this to test where a where a downed router might be or where in the connection a downed router might be So if we go in here for a second and let’s take a look at uh the command prompt here and let’s say I go to trace routegoogle.com Now what’s going to happen is it’s going to start saying all the different hops It’s going to tell me how long it takes to get from one place to the next And we can see also where it’s so right here we’re still in New York You can see NYC I can probably guess this is someplace in my ISP And now it looks like it’s starting to go out get further out And we can see that the amount of time it’s taking is also more and more So between getting between me and and Google you can see how far we’re having to go until we finally get to the Google.com web uh server which would be right here And we know it took about 10 hops Now you can see it has a maximum of 30 hops And we can actually set that in the switches if we need to but I wouldn’t worry about that for the exam And just to show you what it looks like if I’m tracing the local host you can see it only takes one hop obviously because or not even a hop because it’s myself It should be no route to get to me Now going away from the command line for a second I want to talk about what’s called a protocol analyzer or a network analyzer This is an essential tool when you’re running a network It basically gives you a readable report of virtually everything that’s being sent and transferred over your network So these analyzers will capture packets that are going through the network and put them into a buffer zone Now this buffer zone just like the buffer zone we’re dealing with YouTube or Netflix and buffering a video uh is going to hold on to these packets and we can either capture all the packets or we can capture specific packets based on a filter It can then provide us with a easy readable overview of what is contained within each packet This allows the administrator total control of what does and doesn’t pass through the network and can also stop potentially dangerous or unwanted pieces of data to pass through the network undetected And so what you can see here is if this is our cloud or our network we’re going to call this a TCP IP network just because this is basically our our WAN And here let’s say I have one LAN and another LAN I’m going to have a protocol analyzer or network analyzer in between my network and my LAN That way I can analyze exactly what’s going on Some ways this might also take the form of a firewall Now this is different from what’s called a port scanner A port scanner does exactly what it sounds like It basically scans the network for open ports either for malicious or for safety reasons So uh it’s usually used by administrators to check the security of their system and make sure nothing’s left open Oppositely it can be used by attackers for their advantage So uh if a port if I’m on the internal I might use a port scanner to scan my firewall to see what’s going to be allowed through I might also put my port scanner over here and have it try to come in Alternatively a hacker could use a port scanner to go through and scan for open ports If there are any open ports it can then use those to try to get into my system So I can use it either as a white hat or as a black hat White hat means a good hacker Black hat means a bad hacker Now let’s get back into uh our command line for just a second here The name server lookup or NS lookup And again whenever you see NS as in DNS domain name system you can think of that has something to do with name server or a name system It it’s used to basically find out uh what the server and address information is for a domain that’s queried It’s mostly used to troubleshoot domain name service related items and you can also get information about a systems configuration Now DIG actually does the same thing but it’s a little more detailed and it only works with Unix or Linux systems So here’s an example of what the NS lookup would look like And you can see we have NS lookup here And then what did we do Well we asked it for Wikipedia’s name and up it pops the IP address and it also tells us when whether it’s authoritative or non-authoritative Authoritative would be a DNS server that’s somewhere out on the internet that is definitely has all the information Non-authoritative means it might be a local one So if we were to look at this for a second for ourselves let’s do nsookup to go into the utility And now we could for instance look up uh google.com and it’ll tell us all the different IP addresses that are available for google.com Yahoo.com maybe even microsoft.com CNN.com etc etc So you can see all these different ones that are coming through Now notice that CNN.com actually wouldn’t let us out and neither would Microsoft.com That’s because they’re actually blocking the they’re filtering out the type of uh uh ports or protocols that are going to be allowing uh that are going to allow like the ICMP ping So if we were to go out of this for a second and by the way you do that is control C and if I tried pinging microsoft.com you’ll notice that it actually doesn’t come back and that’s because they’re actually shutting out ICMP packets from going in Now another one related somewhat is what’s called ARP or address resolution protocol We actually talked about this previously and it’s really used to find the media access control or MAC address or the physical address for an IP address or vice versa Remember this is the physical address It’s hardwired onto the device The MAC address is the system’s physical address and the IP address is the one again assigned by a server or manually assigned In a way this would be like your phone number and this would be like your social security number which is given to you by the government The way it does this is we’re actually going to send out discovery packets in order to find out the MAC address of a destination system And once it establishes that it sends that MAC address to the sending or receiving computer Now the two computers can now communicate using IP addresses because they can both actually resolve to IP addresses So basically I’m want to send something right So what I’m going to do is I’m going to go out hit a router The router uses ARP in order to get the MAC address to the sending computer And now we can talk directly because now I know what your MAC address and IP address equal Finally the route command is extremely handy and can be used uh fairly often And it basically this shows you the routing table uh which is going to give you a list of all the routes network connections and so on that the user has the option to then edit Now the reason you might want to edit it is if for instance in your router you want to tell it to use one route instead of another So an example here shows us the gateway the mask So I draw these really quickly and the interface and and the sorry the metric as well as the interface And these are all numbers So these might not mean a lot to you but if you had a guide and you knew where they were going if you knew what your interface was for instance is it a wireless interface or was it a your wired interface that would prescribe a specific number The gateway is going to say what gateway you need to get out and the subnet mask And you could actually add specific information to this to create your own routing table And this you would do really not so much on your computer but more if you’re working on a router say a Cisco router so that you can tell it exactly where you want information to be routed So just to recap uh we discussed and demonstrated several TCP IP tools including ping which we’re really going to use to test connectivity And remember you want to hold on to the slash t switch which is going to do it indefinitely Trace route which is going to measure the hops and can also tell you where uh a connection has been lost A protocol analyzer which is going to look at or network protocol analyzer which going to look at all the protocols coming in and can actually filter them in or out a port scanner which can be used to show open ports either as a security precaution or if I’m trying to infiltrate your network The NS lookup which is that name server could also be dig by the way which is on Unix systems and this is going to allow me to get my IP address to a fully qualified domain name ARP address resolution protocol which is specifically going from IP address to MAC address It sort of really allows routing to occur This is really a principle in uh routers And finally the route command which allows us to edit the routing tables and would be really useful if I was using one of my servers as a router You’re not really going to see routing a route command uh on the network plus exam but I guarantee you’ll see all these others mentioned So uh now that we finished up this very brief lesson on TCPIP the tools and the simple services we’re going to go into LAN administration and implementation a bit more in depth Remote access remote networking fundamentals In the last lesson we talked about wide area networks We talked about how they can be implemented what their benefits are how they transfer information some of the technologies we use and so on and so forth Now in this lesson we’re going to talk more about remote networking access Remote networking and WANs actually really go hand in hand And if you think about it more of what we do now more than ever allows us to remote in from home to the WAN the largest WAN in the world being the wide area network of the internet and then access our lands at work This really allows us to not only get stuff done but is changing the landscape of how networking the internet and security have been created and how we continue to work with them So we’re going to talk about this in this module and in the next couple but for this one the first thing we want to do is define what remote networking really is Then we want to identify some of the technologies that we see in place when we discuss remote networking These include VPN which we’ve already discussed in some broad detail or a virtual private network Radius which allows us to authenticate users once they connect and TACax which allows us to keep it all secure So these three are used in enterprise settings to allow someone to remote in from home and connect to the network at work So WANs are networks that are not restrained to one single physical location They’re typically as we’ve discussed many local area networks that are joined together to create one big WAM However this isn’t the only configuration they can have And remote networking is something that ties in really well with wide area networks You see remote networking is the process of connecting to a network without being directly attached to it or physically present at the site In other words a user or group of users can remotely connect to a network without actually being where the network is established So if I were at home and wanted to connect to a network say in China I could actually connect as though I were sitting right in an office in China without actually physically being present This type of thing comes in handy quite a bit Now remote networking doesn’t always happen between two very distant locations In fact it can be used within the same building the same room while traveling And remote networking not only works on a long distance level but on a local network as well For instance suppose that I’m an administrator in my office and I want to access the contents of a user’s computer or I want to restart a server Well instead of having to get up walk up to the fourth floor or down to the basement wherever the server is I could simply remote in to the server and reboot it from there So you can see that it’s a huge time-saving device However it also opens up a lot of possibilities for security issues and so on So here is an example of what uh remote network connectivity could look like The user is in China on the right and they need to connect into the network in New York here on the left So they’re sitting at one physical location and they connect through a WAN which we’re going to call the internet the largest WAN in the entire world and they remotely connect in some sort of way which we’ll talk about usually through something called a VPN using all sorts of public networks and eventually they reach the router at their corporate office and then it’s as if they are actually sitting there connected into the network They can now access resources on local clients or even on the server and all without physically being at the location in New York Now there are a lot of terms we hear when we talk about uh remote networking and remote access Most of them end up being acronyms for the sake of time and convenience But there are three that I want to specifically talk about here that we’re going to talk about in more detail in the coming modules The first is VPN or virtual private network This is something we’ve talked before and we’ll talk about late a little bit later but in essence it extends a LAN or a local area network by adding the ability to have remote users connect to it The way it does this is by using what’s called tunneling It basically creates a tunnel in uh through the wide area network the internet that then I can connect to and through So all of my data is traveling through this tunnel between the server or the corporate office and the client computer This way I can make sure that no one outside the tunnel or anyone else on the network can get in and I can be sure that all of my data is kept secure This is why it’s called a virtual private network It’s virtual It’s not real It’s not physical It’s definitely private because the tunnel makes sure to keep everything out Now the next term we want to talk about is called Radius Radius by the way stands for remote authentication dialin user service I’m going to write that out here Remote authentication Dial inverse user service Now if you notice there’s a dial in Well remote can actually be uh dialing in using a modem We don’t use that much anymore but this is an older service What this does is it allows us to have centralized authorization authentication and accounting management for computers and users on a remote network In other words it allows me to have one server that’s going to be responsible and we’re going to call this the Radius server that’s responsible for making sure once a VPN is established that the person on the other end is actually someone who should be connecting to my network Remember I don’t want to just let anyone connect I want to make sure the person who connects is someone who belongs to my network Generally what we’ll do is we’ll have active directories which is what Microsoft uses to create for instance usernames and passwords and we’ll link that up or sync it with the radius server Sometimes this is done on a separate um a separate uh server sometimes it’s done on the same server Either way once you connect the VPN the VPN then goes to the Radius server The radius server checks the active directory and now I can make sure that only users of the network are allowed onto my network Finally we have something called tacax or terminal access controller access control system It’s really long I’m not going to write it out This is actually a replacement for radius There was another uh replacement for radius by the way It was called diameter And if you’re a math wiz you’ll notice that radius is half of a diameter when we talk about circles But diameter wasn’t really used much TACax on the other hand is a security protocol It allows us to validate information with the network administrator or server and the validation is tested when we try to connect just like with Radius Of course the benefit is TACX is newer and more secure than Radius So it basically does the same thing It’s just a little more powerful All right So this was short but I just wanted to give us an overview of remote networking and we’re going to talk more about that in the coming modules So we talked about remote networking what it is allowing us to access a LAN basically through a WAN whether that WAN is the internet or public switch telephone network It also allows us to access the LAN from a different physical location We can also identify three remote networking technologies The first virtual private network creates a tunnel over the WAN through which we create a virtual network that is also private We also talked about radius and tacax Both of these allow for authentication so we can make sure the person who establishes the VPN is actually allowed on our network authentication authorization and accounting In the last module we started off this lesson by discussing the fundamentals of network security Now a big portion of network security has to do with AAA or authentication authorization and accounting The AAA server on a network is probably one of the most important things when it comes to security and it does quite a bit of work So in this module we’re going to define and discuss these three A’s authentication authorization and accounting in further detail so we know not just what they are but how they’re implemented in a very general way Authentication is the first A It’s used to identify the user and make sure that the user is legitimate Sometimes attackers and bots will try to access a network or secure data by acting like they’re a legitimate user This is where authentication comes into play Any secure network is going to require uh something like a username and password to log in and any data that’s really important or secure needs to be protected Now there are ways of course for these attackers to gather the password and username information but the smart thing for us to do is to change passwords for all users on a network frequently probably every 30 to 90 days Again we have to balance that with how easy it is for someone to come up with a new password and if they’re going to remember the new password they come up with We need to make sure that the passwords are documented in some way Although we want to be careful again because when we write them down and document them that opens up another way they can be stolen and we want to make sure that they’re all secure If an attacker has an outdated password it’s going to do them no good So if we can put this in another way authentication verifies identity This is sort of like uh you have a ID card or driver’s license that provides your identity and authenticates you are who you are One of the reasons we have pictures on our driver’s license or government issued IDs is so that people can look at it and guarantee we are who we are This used to be done with signatures They would look at two signatures make sure they were identical and then we could authenticate the person was actually us Now we’ve moved way past this now We can even use things like fingerprints which more or less authenticate that we are who we say we are So here is another form of authentication You may have encountered this one before when you’re trying to access things on the internet This is called or looks like a capture and it’s used to stop bots from accessing secure data or infiltrating someone’s account or making an account when we don’t want them to So the text in the gray box is difficult to read for a bot It’s actually a picture and it’s very difficult for robots to read this and know exactly what to type in So because of this the capture is usually made different fonts distorted text pictures etc And it can be slightly different for a human to read but not so difficult for them that they can’t actually type it in When you type in the image into here as text then you can basically ensure that you are who you say you are that you are a human rather than a bot Now authorization is the next security level after authentication It’s the second A So once a user has been determined authentic we’ve authenticated their identity They’re going to be allowed onto the network but they can’t just have free reign and do whatever they want We want to make sure that they can only access specific things Remember that concept of least privilege Well we want to make sure that the person who’s on there is only going to access stuff that they are allowed to access So you’re authorized to access only certain things Now there are users such as the admin who can generally access a quite deal more but we don’t want for instance the administrator to have access to the partner’s private email in a law firm and we don’t want someone who works in accounting to have access to marketing So authorization basically provides the information on what the person or IDed person who has been authenticated is authorized to get access to Now authorization procedures can stop users from accessing certain datas services programs etc and can even stop users from accessing certain web pages For instance we sometimes have filters that make sure our kids don’t access very specific information unless they can type in a password that would authenticate that they’re an adult So here’s an example of what a denied web page might look like As you can see the user is being told that an error 403 has occurred Other words the web page has been forbidden It requires you to log on and you have not logged on successfully So you have not authenticated who you are and therefore you are not authorized to have access to specific degree of information Now users other than the administrator will most likely not be authorized to run commands in the command prompt And we’ve looked at this with A+ running things in an administrator mode If the user does they’re probably going to receive an error that looks like this This command prompt has been disabled by your administrator The administrator can deny every other user on the network the ability to use the command prompt because they could do something that they are not authorized to do So it’s up to the administrator to make sure that only authorized users can access the command prompt or do other things on the computer or on the network For instance rebooting computers accessing servers and so on Now the final A we talked about authorization and authentication is accounting Accounting is not the same as in bookkeeping It’s accounting in the sense that everything a user does while on the network has to be accounted for and carefully watched This is sometimes also called auditing Another uh term that gets back to uh accounting in a sort of financial sense but it means something different the users on a network uh can often be one of the biggest of our security concerns Most of the time someone is going to hack our network from inside rather than outside And so keeping track of how users spend their time is one of the most important aspects of network security The accounting function of the AAA servers to do exactly that It watches all of the users and monitors their activity as well as all the resources they’re using These resources could include stuff like bandwidth CPU usage and a lot more Not to mention what websites they’re accessing and so on Now some people say “Hey wait You’re infringing on my right to use the internet.” But if you are at your company using your company’s internet then you have signed most likely an agreement saying you’re only going to use it for specific purposes And you’ve probably also signed an agreement whether you know it or not that allows them to monitor you while you’re using the internet So here’s a representation of what the accounting function of a AAA server does It oversees everything the users are doing and keeps track of what the resources are those users are taking up and how they’re spending their time Now this was a short module but it discussed the AAA and these are three really important concepts you need to know and understand for Network Plus First we looked at authentication Authentication makes sure that the identity has been verified This is just like in a metaphor uh your driver’s license which has a picture ID Next we talked about authorization This is what you are allowed to do This could be just like you’re authorized if you have your driver’s license and you’re 21 and up in the United States to drink So authentication is provided by the driver’s license You are who you say you are And then authorization says whether or not you’re allowed to drink or even drive uh depending on your age and a variety of other circumstances Finally accounting is basically a log of what you do If you get in trouble with the law that’s put on a record That way if you’re pulled over by a policeman let’s say for speeding they can scan your driver’s license and see if you have any outstanding warrants or if you’ve been pulled over in the past In this way accounting provides a background information on you and can make sure that we know what you’re doing on the network what information you’re accessing and also make sure when you’re accessing it and so on Let’s say that we have someone rob our store at midnight and the store is closed Well if your security card was used to get access to the store then we know that either you robbed the store or someone who stole your security card robbed your store IPSec and IPSec policies Having discussed intrusion detection and prevention systems which are mostly having to do with keeping attacks and malicious software off our network I want to talk about something called IPSec or IP security which is a sort of group of protocols and policies that are used to keep the data that we have secure on a network Whenever we talk about security there’s something called CIA the CIA triad that we need to keep in mind C stands for confidentiality meaning only the people we want to see something actually see it The I stands for integrity meaning what we send is what the other party receives It hasn’t been tampered with And finally we have to balance all of this against availability It doesn’t matter if something is super secure if no one can access it So broadening out into this that’s where IPSSEAC comes into play So we’re going to talk about IPSAC defining and discussing what it is and then talk about two protocols that we focus on with IPSec AH and ESP We’re also going to discuss three different services that IPSec uses or serves One is data verification protection from data tampering Again getting into that integrity and private transactions going along with that confidentiality All of this supports availability and the reason we have IPSAC is to make sure that in our security we have available data Finally I want to talk about some of the policies the ways that we use IPSAC So as I mentioned a good amount of the security measures that we use on a network are used to prevent attacks and shield the network from viruses and other malicious software But not all security measures are used for the preventions of this malicious stuff Some are intended to keep data and communications secure within a network While preventing attacks is certainly a part of this there are some security measures that exist to establish secure and safe communication paths between two parties This is what IP security or IP sec protocols do They’re used to provide a secure channel of communication between two systems or more systems These systems can be within a local network within a wide area network perhaps even over a virtual private network Now some people might think that data traveling within a local network is secure but this is only sometimes true Imagine that someone has hacked into our network and we’re sending data across it Well now we want to make sure that the data itself is secure So while the entire network might be protected by firewalls antivirus IDs IPs there might be nothing protecting the actual connection between the two users generally the data that gets sent across the network is not really heavily protected or didn’t used to be So people tend to think that just because their network has a shield around it everything inside it is safe as well But this isn’t the case It’s important to have ipsec protocols in place to secure the data sent and the connections made over a network both local and wide area networks Now there are two main protocols that are categorized in IPSec They are ah or authentication header and ESP the encapsulating security payload Let’s talk a little bit more about what these are As the name states ah or authentication header is used to authenticate connections made over a network It does this by checking the IP address of the users that are trying to communicate and make sure that they’re trusted It also checks the integrity of the data packets that are being sent In other words is this the data that we actually intended and was it received properly The other one encapsulating security payload or ESP is used for encryption services which I think we’ve talked about It encrypts data that’s being sent over a network using ah to authenticate the users ESP will only give the keys to the users that have been authenticated So I make sure to authenticate using ah that this is the user I want to give something to And then the ESP does the encryption for the people who have been authenticated providing keys only to the people who meet the first condition Now if this seems like a broad overview of these two it is We’re not going to see this a whole lot on the Network Plus exam Maybe one question but it’s not really worth going into depth because that’s what Security Plus is going to do And when you talk about security plus you’re really going to talk about these and IP security in more depth then now there are a few benefits and services that IPS sec protocols provide The first service is data verification This service ensures that the data that is being sent across the network is coming from a legitimate source or a legitimate place They make sure that the end users are the intended users and they keep an eye on packets as they travel across the network The next service that IPSec is going to provide is protection from data tampering Again that integrity The service makes sure that while data is in transit nothing changes This could mean the data somehow becomes corrupted or that someone literally tampers with it Again while IPSec protocols provide secure communications within the network they don’t actually stop an attacker from entering the network So while there is a chance of an attacker on the network they can’t tamper with the data as it travels through because IPS is going to make sure that doesn’t happen Finally IPSec provides private transactions over the network This means that data is unreadable by everyone except the end users This is where that authentication comes in and where confidentiality comes into play For example if Mike and Steve have to send some private banking information to each other the service makes sure that Mike and Steve are the only people who can read it This isn’t happening at any level that you can see It’s happening all within the protocols that already exist When we talked much earlier about IP version 4 versus IP version 6 one of the great benefits of IP version 6 is it has all the IPS sec stuff built in So all of this is happening automatically within our new version of IP version 6 It’s not even something we need to really worry about just something we need to know is taking place so we can be a little more sure that our data is actually being secured So here is what IPSeack might look like if they were connecting two LANs to make a WAN Though the two networks have their own firewalls and protection systems they still have to connect through a public network which we know isn’t the safest thing This is especially true when the public network is the internet Now using IP sec the two LANs are going to create a tunnel of communication through the network or through the internet This tunnel is secure and only accessible by people inside their network This IPSec tunnel by the way is what we’re referring to when we talk about VPN or virtual private networks So when we set up IPSe the service doesn’t just configure itself necessarily There’s some things that have to be put into place for the services to run properly These are called policies and policies uh is what configures the services that IPSec provides They’re used to provide different levels of protection data and connections based on what get what is getting passed through them In other words just like with passwords we have the passwords and we know they’re built into Windows but unless we set some sort of policy that tells the users how their passwords have to function they might not be used very well Someone might just use the password password which isn’t even a safe password So we have a password policy that ensures that people have a certain length uh history and certain characters included in their passwords The same thing sort of goes with IPSec Now there are some important elements that we have to address when setting up IPSec policies First we have filters that are put into place The filters determine which packets should be secure and which can be left alone Now every filter addresses a different type of packet So there’s generally a good amount of different types of filters All of these filters get compiled into a filter list where the administrator can easily change and reconfigure the filters to address the needs of their network Now again the reason we’re going to want to have filters is because the more security Just like the more layers you have on if it’s cold outside the more data it takes up and the longer it takes to decode So the less security we have the faster the data is going to travel But the more security uh the less easy it is to tamper with So we need to weigh this Stuff like browsing on the internet might not be something we need to secure a lot Whereas we probably want to secure uh for instance email a lot more or even bank social security numbers etc etc Next policies have to be provided the proper network information This involves what security methods connection types and tunnel settings are being used The security methods are basically algorithms that are used in encrypting and authenticating the data Connection types determine whether the policies are going to handle a local area network a WAN or a VPN In other words IPSec needs to know what type of connection I have here so it knows what level of security to put into place You can imagine that with a wide area network or VPN we need more security than with a LAN All right So although this might have been short in duration we covered a lot of important things First we talked about the fact that IPSec exists Remember IPSE stands for IP security And it’s really not its own protocol What it is is a series or a group of protocols services etc that ensure security over the IP protocol or the internet protocol We also talked about two of the ways we do this One is the AH protocol and one is the ESP protocol Remember AH stands for authentication header As the name implies it’s a header in the IP packet that authenticates to make sure the users who are about to communicate are the ones for whom it’s intended and who are sending ESP on the other hand which stands for encapsulating security payload is literally going to encapsulate the data in an encrypted form and it’ll only release this encrypted information to someone who has been authenticated to receive it And remember to do this we use keys both public and private We also discussed the three different IPX services that are provided including data verification which ensures that the data packets being sent are coming from legitimate places Protection from tampering which ensures the integrity of our data that it has not been tampered with either tampered with from uh say an attacker or the data might have just become corrupted Finally we ensured that we’re having private transactions meaning that the data is confidential between only the people who need to be having it And lastly we discussed IPSec policies Some of the things that we need to have when we’re creating our policies for IP security For instance we need to know the type of network we’re on and also filters so that the appropriate level of security can be applied to the appropriate type of data

By Amjad Izhar
Contact: amjad.izhar@gmail.com
https://amjadizhar.blog
Affiliate Disclosure: This blog may contain affiliate links, which means I may earn a small commission if you click on the link and make a purchase. This comes at no additional cost to you. I only recommend products or services that I believe will add value to my readers. Your support helps keep this blog running and allows me to continue providing you with quality content. Thank you for your support!








